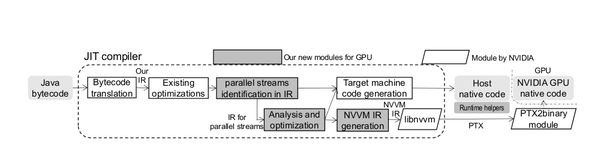
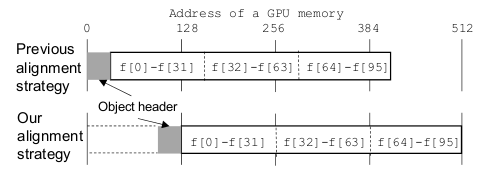
J9对GPU的支持中,我们说的内存优化是指的是GPU中的array(i.e., device memory)的处理, 而非host memory中的array。在cuda原先memory allocation方法中 。原先的管理方式是直接讲array object (array header and array body) 放入连续的一块地址中(starting from 0)。在新的优化,实际上重新对array object进行placement 使得body从128 的整数位(e.g., index 31) 开始。如下图:
这么做的理由主要是基于两种条件: a) 内存的操作更多的是对元素中read and write,对array header的操作并没有那么频繁(对比而言), 所以header的读写的重要性不高; b) 在128 index对齐后,读或者写可以在一个GPU指令周期内完成,而前者需要两个指令周期(第一个: 0-127, 第二个周期: 128-384 ).
当然,除了array aligning, J9 也对内存其他方面进行的优化(不细说了),比如基于jit对内存region 读写进行识别, 对指令进行re-order, 以达到high memory cache hit in GPU, 又或者减少不必要的复制指令 for copying from GPU memory to host memory,有或对 array header elimination.
可以拿出来说的是 cross lambda method calling. Exactly speaking, the caller is inside of lambda while the callee is out of lambda closure. 比如下面这个例子:
public class Sample{ public void myMethod(args...){} public void anotherMethod(){ intSteam...forEach( i ->{ myMethod(receiver, other-args); obj.anotherMethod();.. }); } public void anotherMethod(){} }
b) GPU上还要在runtime 决定 方法的具体实现方法(Java上若无显示标注方法是 invokevirtiual)。 =_=
为了决定具体某个方法的实现,the receiver of a method call 和 virtual method table 需要在runtime时候从host memory 复制到device memory中去。为了使得程序跑的正确,这两个Gap将会kill GPU的效率。
To resolve both Gaps, J9中JIT 编译器直接进行inline Caching (IC)优化(Akihiro认为是Method Inling). 在VM中,Inline Caching之前是SELF language中(For detail, please refer Dr Urs Hölzle's PhD thesis [3])。
简单的归纳下就是在生成NVVM的时候,先直接假定 the type of method call receiver是哪一种,然后将被调用的方法实现直接inline到方法调用处。为了生成代码的正确性,在原先call site之前插入一个guard (中文不知道如何翻译??)进行检测。若检测没有成功,则jmp到原先低速的方法(也就是这个时候GPU停下来去要求CPU执行:看当前receiver具体是哪路神仙(这个GPU也可以做,但是需要先copy from host memory to device memory),CPU执行callee's method). 所以对于上面lambda内 obj.anotherMethod(); 变成了
if(receiver is someType){ SomeType's anotherMethod real Implementation and will be executed at GPU kernel. }else{ invoke receiver.anotherMethod(..) //execute on CPU }
【3】Urs Hölzle, Adaptive Optimization for Self: Reconciling High Performance with Exploratory Programming. Ph.D. thesis, Stanford, CA, USA, 1995, UMI Order No. GAX95-12396.
【4】Kazuaki Ishizaki, Akihiro Hayashi, Gita Koblents and Vivek Sarkar, Compiling and Optimizing Java 8 Programs for GPU Execution/
【5】Akihiro Hayashi, Kazuaki Ishizaki, and Gita Koblents, Machine-Learning-based Performance Heuristics for Runtime CPU/GPU Selection. PPPJ 2015.