前面讲过激光雷达和摄像头的融合方法,这里列一些纯激光雷达的目标检测工作。
注:因为文章方法太多,分成上下两部分。
"Vehicle Detection from 3D Lidar Using FCN"
是百度早期自动驾驶组在2016年工作。
将全卷积网络技术移植到三维距离扫描数据检测任务。具体地,根据Velodyne 64E激光雷达的距离数据,将场景设置为车辆检测任务。 在2D点图呈现数据,并使用单个2D端到端全卷积网络同时预测目标置信度和边框。 通过设计的边框编码,使用2D卷积网络也能够预测完整的3D边框。
2D点图的形成通过如下公式:
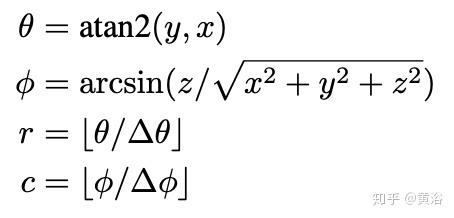
其中p =(x,y,z)表示3D点,(r,c)表示其投影的2D图位置。 θ和φ表示观察点时的方位角和仰角。 Δθ和Δφ分别是连续光束发射器之间的平均水平和垂直角分辨率。 投影点图类似于圆柱图像。 用2-通道数据(d,z)填充2D点图中的(r,c)元素,其中d =(x ^ 2 + y ^ 2)^ 0.5。
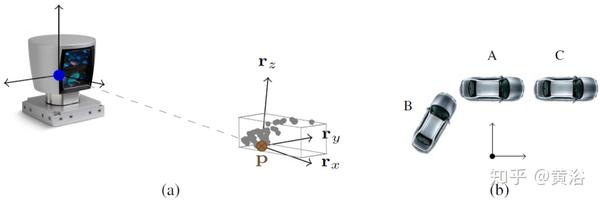
如图所示:(a)对于每个车辆点p,定义一个以p为中心的特定坐标系;坐标系的x轴(rx)与从Velodyne原点到p(虚线)的光线一致。 (b)关于观察车辆时的旋转不变性的说明,载体A和B具有相同的外观。
下图是FCN结构图:
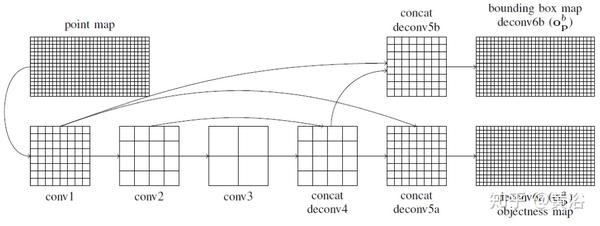
目标度图deconv6a由对应于前景,即位于车辆上的点,以及背景,的2个通道组成。 2个通道由softmax标准化表示置信度。
边框图的编码需要一些额外的转换。
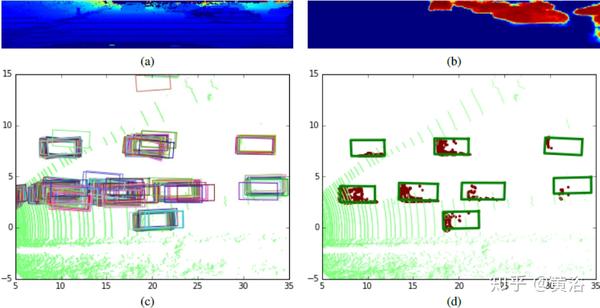
下图在不同阶段生成数据的可视化结果。 (a)输入点图(d, z),其中 d 通道可视化。 (b)FCN中deconv6a输出口目标度分支输出的置信度图。 红色表示更高的置信。 (c)对应于预测为正的所有点的边框候选,即(b)中的高置信度点。 (d)非最大抑制后的剩余边框。 红点是车辆的基本点供参考。
"VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection"
Apple的工作:为消除对3D点云的手动特征工程的需求,提出VoxelNet,一种通用的3D检测网络,可将特征提取和边框预测统一到单步端到端可训练的深度网络中。
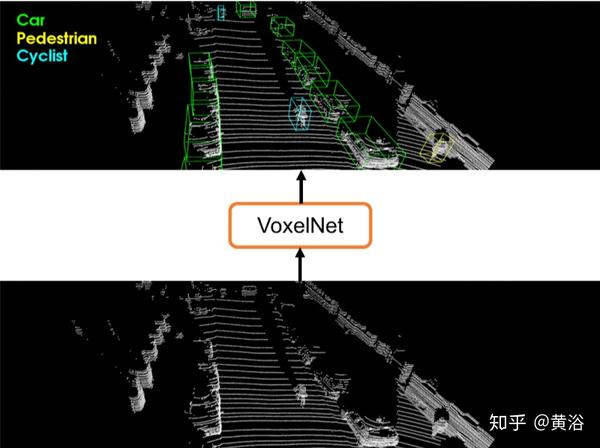
具体而言,VoxelNet将点云划分为等间距的3D体素,并通过体素特征编码(VFE)层将每个体素内的一组点转换为统一的特征表示。
通过这种方式,点云被编码为描述性体积表示,然后将其连接到区域建议网络(RPN)以生成检测。
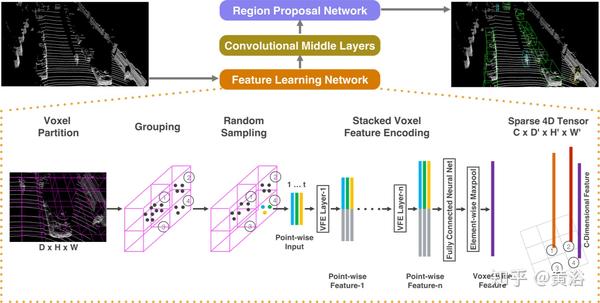
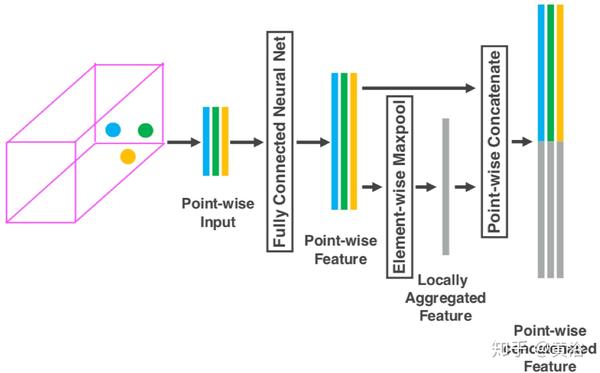
下面是VFE层的结构:
如图是RPN的结构:
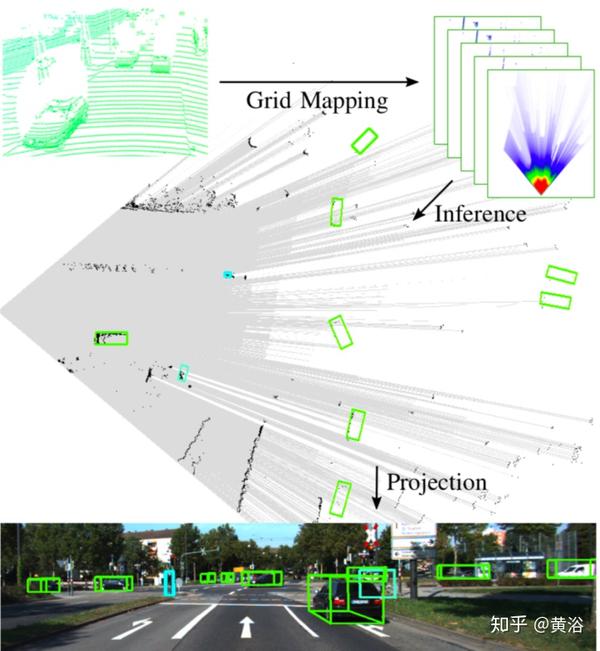
"Object Detection and Classification in Occupancy Grid Maps using Deep Convolutional Networks"
基于网格图的环境表示,非常适合传感器融合、自由空间的估计和机器学习方法,主要使用深度CNN检测和分类目标。
作为CNN的输入,使用多层网格图有效地编码3D距离传感器信息。
推理输出的是包含一个带有相关语义类别的旋转边框列表。
如图所示,将距离传感器测量值转换为多层网格图,作为目标检测和分类网络的输入。 从这些顶视图网格图,CNN网络同时推断旋转的3D边框与语义类别。 将这些框投影到摄像机图像中进行视觉验证(不是为了融合算法)。汽车被描绘成绿色,骑自行车的人是海蓝宝石,行人是青色。
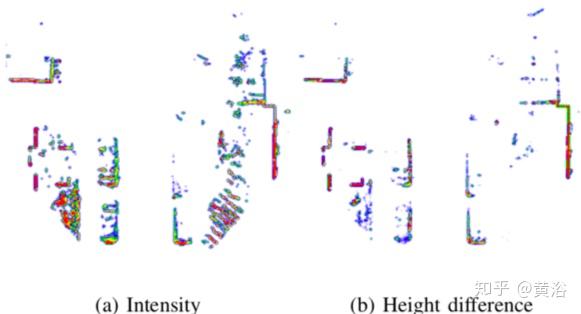
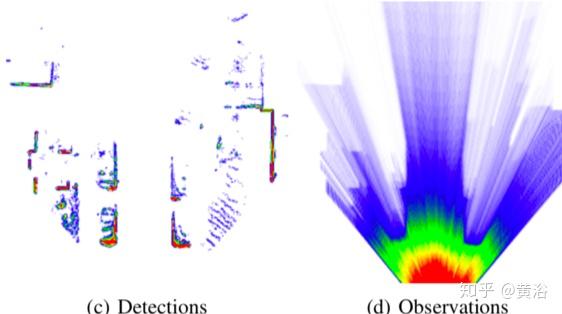
以下是获得占有网格图(occupancy grid maps)的预处理。
由于仅在摄像机图像中有标记目标,因此删除不在摄像机视野中的所有点。
应用地面分割并估计不同的网格单元特征,得到的多层网格图的大小为60m×60m,单元格大小为10cm或15cm。如所观察到的,在大多数情况下地面是平坦的,因此将地平面拟合到代表点集。
然后,使用完整点集或非地面子集来构造包含不同特征的多层网格图。

"RT3D: Real-Time 3-D Vehicle Detection in LiDAR Point Cloud for Autonomous Driving"
这是一种实时三维(RT3D)车辆检测方法,利用纯LiDAR点云来预测车辆的位置、方向和尺寸。
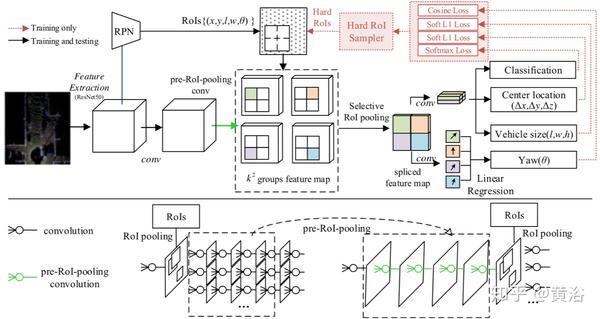
设计的是两步检测法,文中应用pre-RoI pooling卷积,将大部分卷积运算移到RoI池之前,只留下一小部分,这样可以显着提高计算效率。
姿势敏感的特征图设计特别通过车辆的相对姿势激活,带来车辆的位置、方向和尺寸的高回归精度。
文中声称RT3D是第一款在0.09秒内完成检测的LiDAR 3-D车辆检测工作。
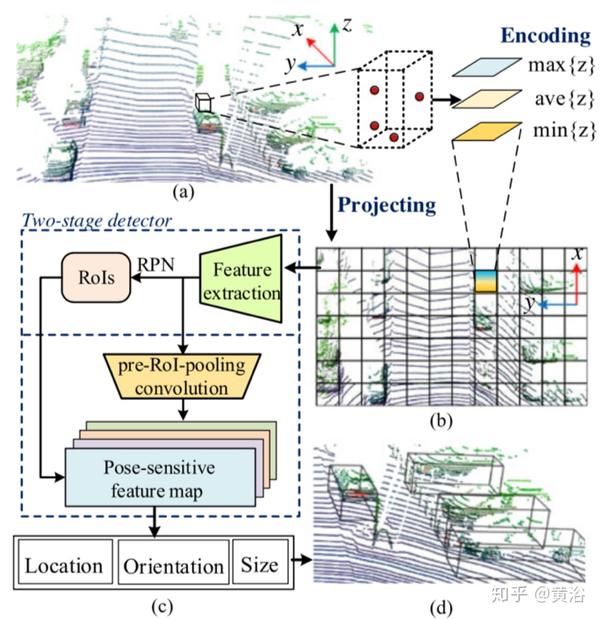
下图是RT3D的结构图:
"BirdNet: a 3D Object Detection Framework from LiDAR information"
这个基于LiDAR的3D物体检测流水线,需要三个阶段:
- 首先,激光数据被投射到鸟瞰图的新单元编码中。
- 之后,通过最初设计用于图像处理的卷积神经网络,估计平面目标的位置及其航向。
- 最后,后处理阶段计算面向3D的检测。
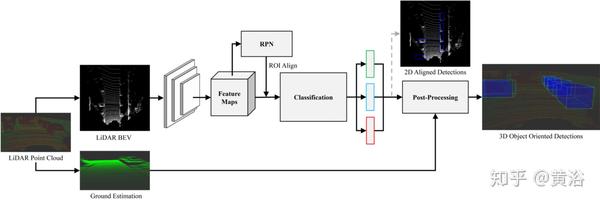
上图可以看到预处理的ground estimation模块,检测模块中的RPN。
下图是一些结果:

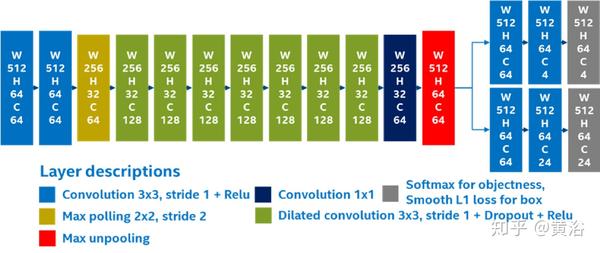
"LMNet: Real-time Multiclass Object Detection on CPU using 3D LiDAR"
这是一种优化的单步城市环境目标深度CNN检测器,不过仅使用点云数据。
随着深度的增加,网络结构采用扩散卷积(dilated convolutions)逐渐增加感知场(perceptive field ),这样将计算时间减少约30%。
输入包括无组织点云数据的5个透视表示。网络输出目标度图和每个点的边框偏移值。
在3个轴的每个轴采用反射值、范围和位置等,有助于改善输出边框的位置和方向。
使用桌面GPU的执行时间为50 FPS,英特尔酷睿i5 CPU的执行时间高达10 FPS。
如图是点云信息编码:

这个是LMNet的结构图:
下表是扩散卷积的参数:

"HDNET: Exploit HD Maps for 3D Object Detection"
高清(HD)地图提供强大的先验知识,可以提高3D目标探测器的性能和鲁棒性。
这是一个从高清地图中提取几何和语义特征的单步目标探测器。
由于地图可能不是随时可用,因此地图预测模块会根据原始LiDAR数据动态地估算地图。
整个框架以每秒20帧的速度运行。
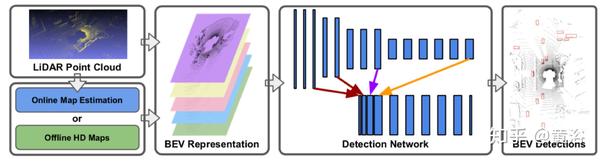
下图是几何和语义高清地图信息的鸟瞰图LiDAR表示:(a)原始LiDAR点云;(b)结合几何地面先验知识;(c)LiDAR点云的离散化;(d)结合语义道路先验知识。

下图左边是目标检测架构图,而右边是在线地图估计架构:
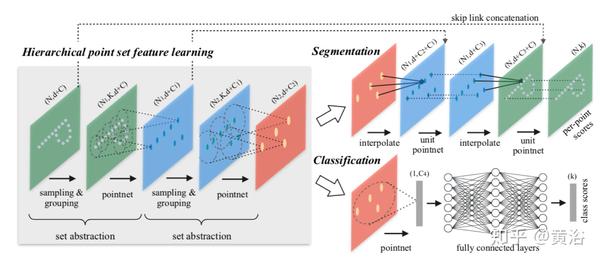
"PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation "
CVPR2017发表。
点云是一种重要的几何数据结构。 由于其不规则的格式,大多数研究人员将这些数据转换为常规3D体素网格或图像集合。 然而,这会使数据不必要地大量增加并导致问题。
本文设计了一种神经网络,它直接消费点云数据,并且很好地尊重输入的点置换不变性。 网络名为PointNet,为从目标分类、部分分割到场景语义分析等应用程序提供统一的体系结构。
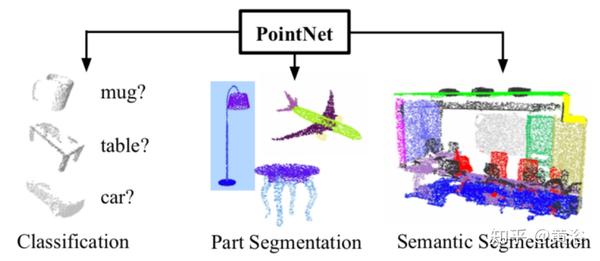
下图是PointNet架构:分类网络将n个点作为输入,应用输入和特征变换,然后最大池化来聚合点特征。 输出是k类的类分数。 分割网络是分类网络的扩展。 它连接每个点数的全局和局部特征和输出。
"PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space"
PointNet不会捕获由度量空间点引入的局部结构,限制了它识别细粒度模式的能力和对复杂场景的泛化能力。在这项工作中,引入了一个分层神经网络PointNet++,将PointNet递归地应用于输入点集的嵌套分区。通过利用度量空间距离,网络能够通过增加上下文尺度来学习局部特征。
进一步观察发现:通常以不同的密度对点集进行采样,这样在均匀密度训练的网络上的性能大大降低,所以提出了集合学习层(set learning layer)以自适应地组合来自多个尺度的特征。
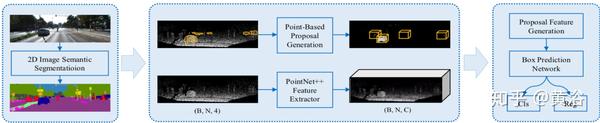
"IPOD: Intensive Point-based Object Detector for Point Cloud"
这是基于原始点云的3D对象检测框架,IPOD。
它为每个点生成目标提议,这是基本单元。采用一种端到端可训练架构,提议中的所有点特征从骨干网络中提取,这种提议特征用于最终边框推断。(注:骨干网络是PointNet++)
注意,这些特征包含上下文信息,而精确的点云坐标能改善性能。
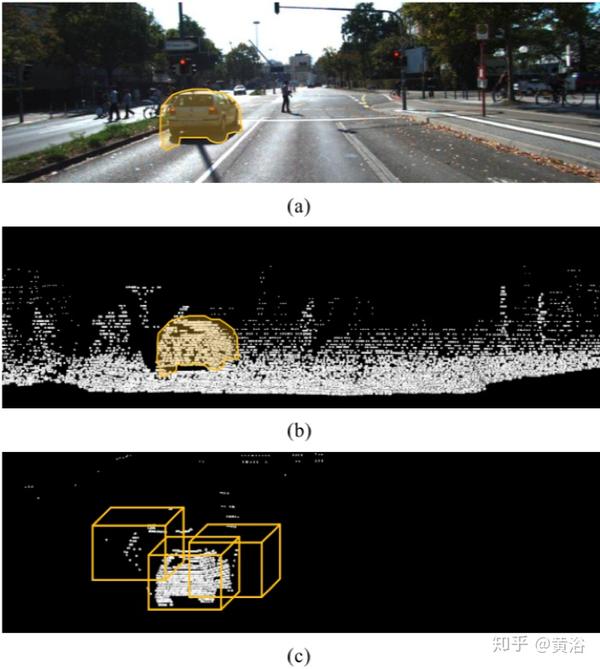
如下图是基于点的提议生成的插图: (a)图像上的语义分割结果。 (b)点云上的预测分割结果。 (c)NMS之后正样本点的基于点提议。
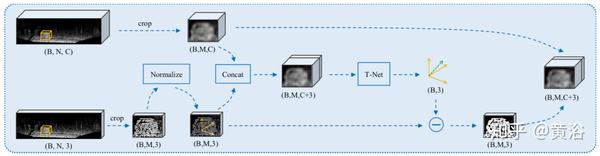
如下是提议特征生成模块的示意图。 它结合了位置信息和上下文特征,用于生成从内部点的质心到目标实例对象的中心偏移。 为了使特征对几何变换更加鲁棒,预测的残差被添加回位置信息。
如图是主干网络(左)和边框预测网络(右)的架构图:
"PIXOR: Real-time 3D Object Detection from Point Clouds"
该方法通过鸟瞰图(BEV)场景表示更有效地利用3D数据,并提出PIXOR(ORiented 3D object detection from PIXel-wise NN predictions)3D目标检测方法。这是一种无需提议的单步检测器,从像素方式的神经网络预测中解码出面向3D目标估计。
其输入表示、网络架构和模型优化,专门用于平衡高精度和实时效率。
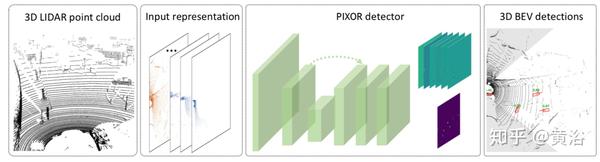
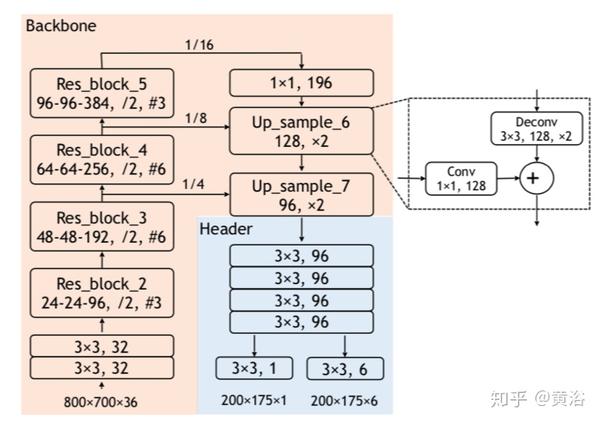
下图是PIXOR架构图:
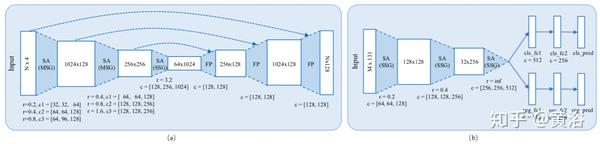
"DepthCN: Vehicle Detection Using 3D-LIDAR and ConvNet"
这是基于假设生成(HG)和假设验证(HV)范例的车辆检测。
输入到系统的数据是3D-LIDAR获得的点云,其被变换为致密深度图(DM)。
解决方案首先删除地面点,然后进行点云分割。然后,将分割的障碍物(目标假设)投射到DM上。边框作为车辆假设(在HG步)拟合成分割目标。
边框用作ConvNet的输入,分类/验证为"车辆"类的假设(在HV步)。
如下是DepthCN的算法流程图:
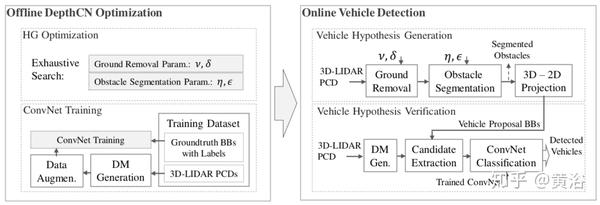
如图是一些结果示意图。顶部:检测到的地面点用绿色表示,在摄像机视野之外的LIDAR点以红色显示。 底部:以2D边框的形式表示的投影的聚类和HG。 右边:缩放视图,垂直橙色箭头表示相应的障碍物。
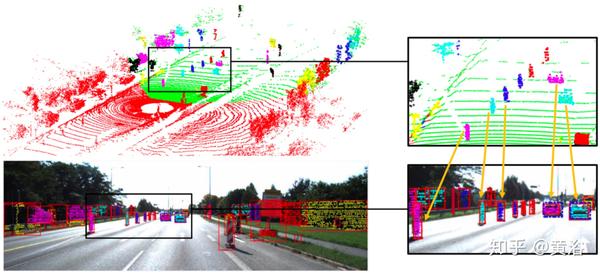
"SECOND: Sparsely Embedded Convolutional Detection"
这种网络改进稀疏卷积方法,显着提高了训练和推理的速度。
它引入一种角度损失的回归函数来改善方向估计性能,还有一种数据增强方法,可以提高收敛速度和性能。
提出的网络在KITTI 3D对象检测基准上产生SoA结果,同时保持快速的推理速度。
如图是算法流程图:检测器将原始点云作为输入,转换为体素特征和坐标,并应用两个VFE(体素特征编码)层和一个线性层;应用稀疏CNN并且采用RPN生成检测。
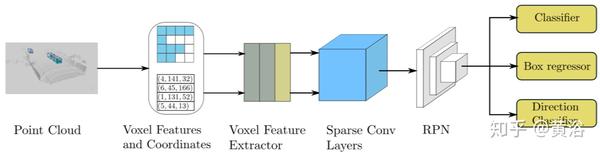
下图给出更多的算法细节:稀疏卷积算法在上图,GPU规则生成算法在下图。
其中Nin表示输入要素的数量,Nout表示输出要素的数量。 N是聚集的特征的数量。 Rule是规则矩阵,其中Rule [i,:,:]是与卷积内核中的第i个核矩阵相对应的第i个规则。 除白色之外的颜色框表示具有稀疏数据的点,而白色框表示空点。
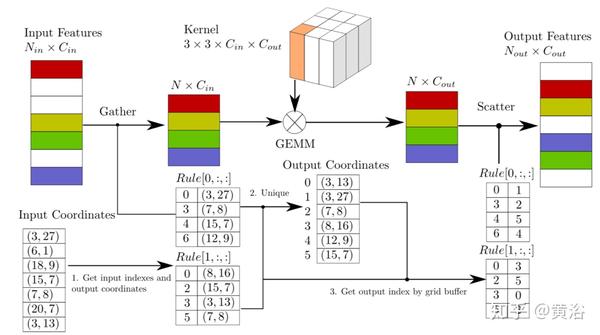
下图是稀疏中间特征提取器的结构。 黄色框表示稀疏卷积(sparse convolution),白色框表示子流形(submanifold)卷积,红色框表示稀疏-密集层(sparse-to-dense layer)。 该图的上半部分显示了稀疏数据的空间维度。
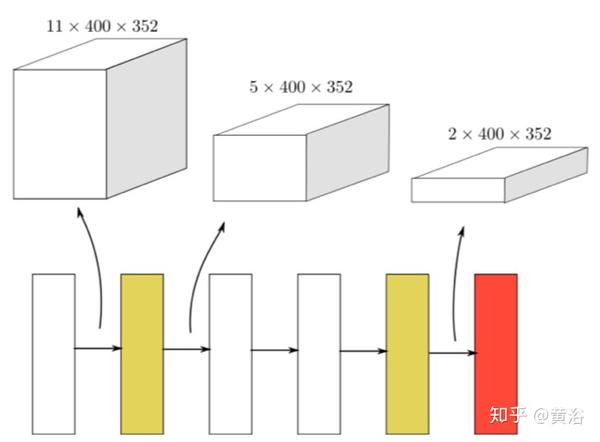
如下是RPN的架构图:
这是一些在KITTI数据的检测结果图:

"YOLO3D: E2E RT 3D Oriented Object Bounding Box Detection from LiDAR Point Cloud"
基于2D透视图像空间中一次性回归元架构的成功应用,这里将其扩展为从LiDAR点云生成定向的3D对象边框。
这个想法是扩展YOLO v2的损失函数成为一个将偏航角、笛卡尔坐标系的3D框中心和框高度包括在内的直接回归问题。
这种公式可实现实时性能,对自动驾驶至关重要。
在KITTI,它在Titan X GPU上实现了实时性能(40 fps)。
投射点云以获得鸟瞰网格图。从点云投影创建两个网格地图。第一个要素图包含最大高度,其中每个网格单元(像素)值表示与该单元关联的最高点的高度。第二个网格图表示点的密度。

在YOLO-v2中,使用k-means聚类在真实目标框的宽度和长度上计算锚点。
使用锚点的背后,是找到盒子的先验,那么模型可以预测修改。
锚点必须能够覆盖数据中可能出现的任何方框。
选择不使用聚类来计算锚点,而是计算每个目标类别的平均3D框尺寸,并使用这些平均框尺寸作为锚点。
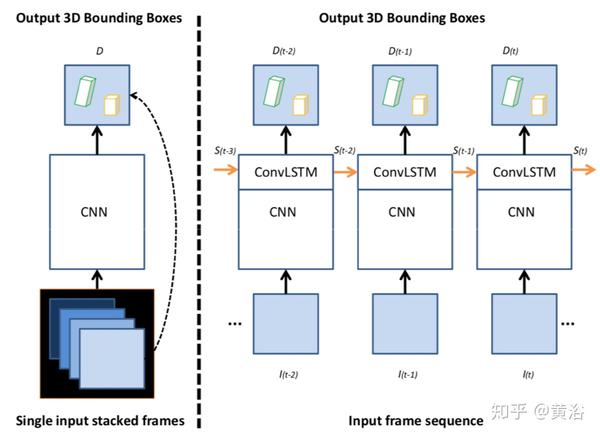
"YOLO4D: A ST Approach for RT Multi-object Detection and Classification from LiDAR Point Clouds"
在YOLO4D,3D LiDAR点云随着时间的推移聚合为4D张量; 除了时间维度之外的3D空间维度,基于YOLO v2架构,被馈送到一次全卷积检测器。YOLO3D与卷积LSTM一起扩展。 用于时间特征聚合。
除了长度(L),宽度(W),高度(H)和方向(偏航)之外,输出还是定向的3D目标边框信息,以及目标类和置信度分数。其中两种不同结合时间维度的技术被评估:递归( recurrence )和帧堆叠(frame stacking)。
如下图,左边是帧堆叠,右边是卷积LSTM。
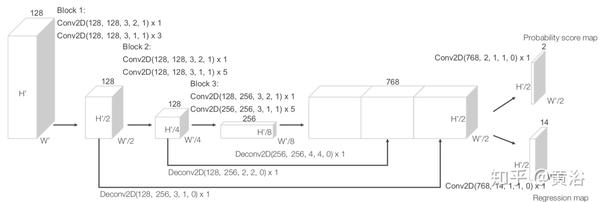
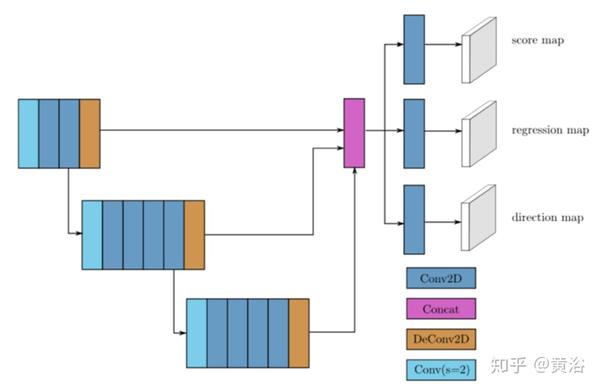
"Deconvolutional Networks for Point-Cloud Vehicle Detection and Tracking in Driving Scenarios"
这是一个完整的车辆检测和跟踪系统,仅适用于3D激光雷达信息。
检测步骤使用CNN,接收由Velodyne HDL-64传感器提供的3D信息特征表示作为输入,并返回其是否属于车辆的逐点分类。
然后,对分类的点云几何处理,生成一个多目标跟踪系统的观测值,其通过多个假设扩展卡尔曼滤波器(MH-EKF)实现,主要是估计周围车辆的位置和速度。
如下图所示:点云的编码表示送入模型,每个点计算其属于车辆的概率; 然后,对分类的点进行聚类,产生可信赖的观察结果,这些观察结果被馈送到基于MH-EKF的跟踪器。
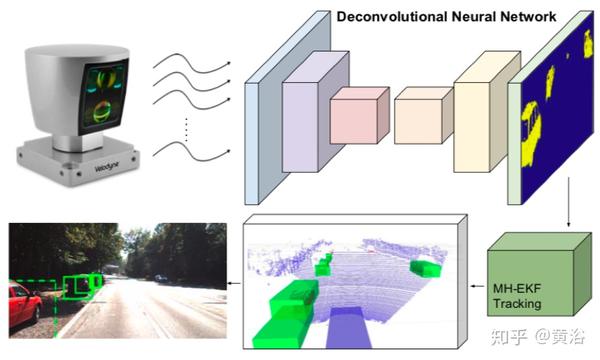
要获取检测器一个有用的输入,通过变换G(·)将3D点云原始数据投影到一个包含距离和反射信息的特征化图像表示中 。
先在3D Velodyne信息投影基于图像的Kitti轨迹(tracklet),然后在所选点上再次应用变换G(·),这样获得用于学习分类任务的真实数据,如下图所示。
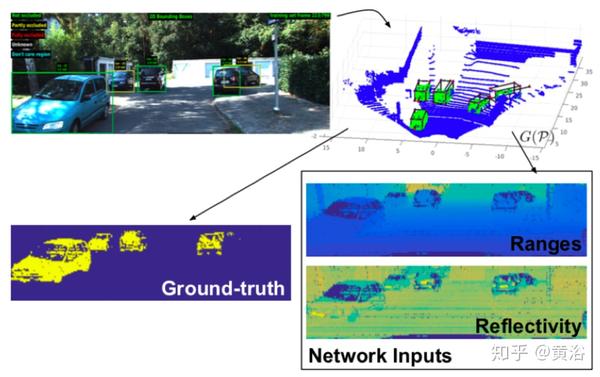
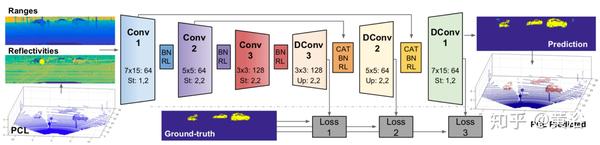
下图是网络架构图:该网络仅包含卷积层和去卷积层,每个块后面是BN和非线性ReLU;前3个块根据车辆检测目标进行特征提取,控制感受野和产生的特征图大小;接下来3个反卷积块扩展了信息实现逐点分类;在每次去卷积之后,而在应用归一化和非线性ReLU之前,来自网络下半部的特征映射被连接(CAT),从而提供更丰富的信息和更好的表现;在训练期间,在不同的网络点计算3个损失函数。
下图显示了原始输入点云、深度探测器输出、最终跟踪的车辆以及提交用于评估的RGB投影边框。

"Fast and Furious: Real Time E2E 3D Detection, Tracking and Motion Forecasting with a Single Convolutional Net"
这是一个深度神经网络,给定3D传感器捕获的数据,共同推理3D检测、跟踪和运动预测。
通过共同推理这些任务,整个方法对于遮挡以及距离稀疏数据更加鲁棒。
通过3D世界的鸟瞰图表示,它在空间和时间上执行3D卷积,这在内存和计算方面都非常有效。该方法可以在短短30毫秒内完成所有任务。
如下图是叠加时间和运动预测数据。 绿色:带3D点的边框。 灰色:没有3D点的边框。

如图展示的是FaF(Fast and Furious)工作,需要多个帧作为输入,并执行检测、跟踪和运动预测。
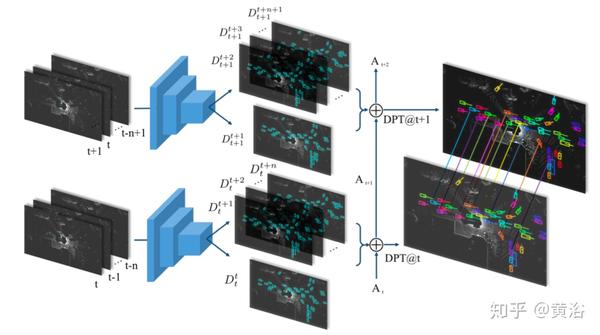
下图是时域信息建模:一个是前融合,另一个是后融合。
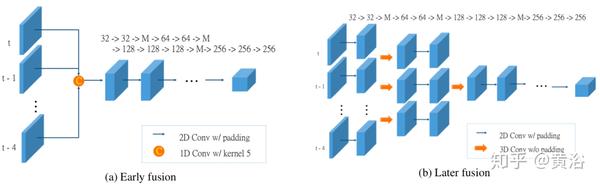
下图是运动预测示意图:

"PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud "
PointRCNN是一种深度NN方法,从原始点云进行3D对象检测。
整个框架由两步组成:
第一步为自下而上的3D提议生成;
第二步用在规范化坐标中细化提议以获得检测结果。
第1步的子网络,不是从RGB图像生成提议或将点云投射到鸟瞰图或体素,而是通过分割点云直接从点云中生成少量高质量的3D提议,整个场景分为前景和背景。
第2步的子网络,将每个提议的合并点转换为规范坐标,学习局部空间特征,其与在第1步中学习的每个点的全局语义特征相结合,用于精确的边框细化和置信度预测。
如下图:该方法不是从鸟瞰图和前视图的融合特征图或RGB图像生成提议,而是自下而上的方式直接从原始点云生成3D提议。
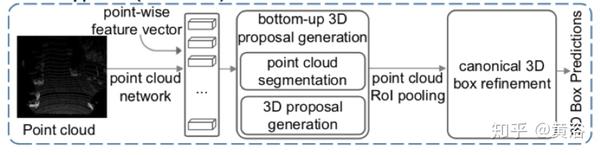
如图是PointRCNN架构。 整个网络由两部分组成:(a)自下而上的方式从原始点云生成3D提议。 (b)规范坐标下细化3D提议。
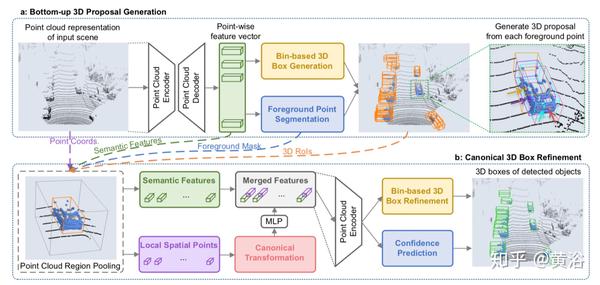
"PointPillars: Fast Encoders for Object Detection from Point Clouds"
该方法将点云编码为适合检测流程的格式。采用两种类型的编码器:固定编码器往往速度快但牺牲精度,而从数据中学习的编码器更准确,但速度更慢。
PointPillars是一种编码器,它利用PointNets来学习在垂直列,也叫柱子(pillars),组织的点云的表示。虽然编码特征可以与任何标准2D卷积检测架构一起使用,但运行一种精益下游网络(lean downstream networ)。
尽管只使用了激光雷达,但是完整的检测管道明显优于SoA,即使在融合方法中也是如此,对3D和鸟瞰KITTI基准测试中胜出。
它在62Hz下运行时实现了这种检测性能,更快的版本与105 Hz速度的现有技术相匹配。
如图是网络概述。 网络的组件包括支柱特征网络(Pillar Feature Network,),骨干网络(2D CNN)和SSD(Single Shot Detection)检测头。 原始点云被转换为堆叠的柱张量(pillar tensor)和柱索引张量(pillar index tensor)。 编码器使用堆叠柱来学习一组可以发散回CNN的2D伪图像特征。 检测头使用骨干网络的特征来预测物体的3D边框。
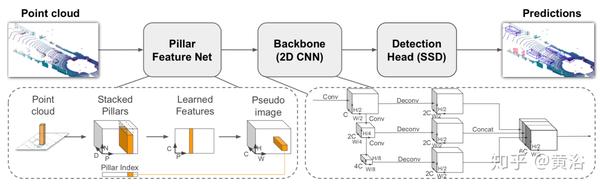
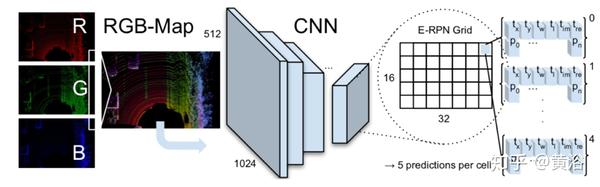
"Complex-YOLO: An Euler-Region-Proposal for Real-time 3D Object Detection on Point Clouds"
Complex-YOLO,是一个仅用点云数据的实时3D物体检测网络。它通过特定的复杂回归策略扩展YOLOv2网络(这是以前一种用于RGB图像的快速2D标准物体检测器),估计笛卡尔空间中的多类3D边框。
提出一个特定的欧拉区域 - 提议网络(Euler-Region- Proposal Network,E-RPN),通过对回归网络添加虚部和实部,来估计对象的姿态。
该网络最终位于封闭的复数空间中,避免了单角度估计所产生的奇点。 E-RPN支持在训练期间的泛化。
Complex-YOLO是一种非常有效的模型,它直接在基于激光雷达的鸟瞰视角RGB-图上运行,以估计和定位精确的3D多类边框。 下图显示了基于Velodyne HDL64点云(例如预测目标)的鸟瞰图。

如图是Complex-YOLO流水线。 这是一个用于在点云上快速准确地进行3D边框估计的流水线。 RGB-图被馈送到CNN。
E-RPN网格在最后一个特征图上同时运行,并预测每个网格单元五个框。 每个框预测由回归参数t和目标度得分p组成,具有一般概率值p0和n个类别得分p1 ... pn。
关于基于激光雷达点云用深度学习的3D目标检测工作,剩下的在下部分介绍了。
来源:知乎 www.zhihu.com
作者:黄浴
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载
















