一提算法,涂抹二字可能就冒出来了,接着就是鄙视手机的balabala,这种不看前提就开喷的风气不知道是什么时候兴起的,当然也怪手机宣传总是作妖。可是让算法来背锅显然是不科学的,因为对于摄影这个已有近200年历史的"老话题"来说,真正进入数字时代也不过寥寥十数年,从胶片到卡片机,到单反相机,再到手机,光学物理虽也在不断摸索前进,但摄影硬件技术发展的天秤早已倾向于以数字算法为核心,而且别忘了,算法也是可以用于相机而不仅仅是手机。
一个简单的问题:月光下拍摄的照片,要怎样才能清晰地分辨细节?按照传统的摄影逻辑,大光圈+长曝光,或许还要配上高ISO才能兼顾出片质量和效率,但如果拍摄对象是动态的呢?那就只能继续加大光圈,继续加ISO来保证快门速度足够高了,而这会引发一个很明显的问题,月光下的照度其实也就0.1-0.3lux,这种照度下以ISO 409600拍摄才能获得勉强能"显像"的照片,但此时的噪点和色彩漂移已经基本失控,后期都补不回来,以下为实拍示例:

照片a,1/30秒,F5.6,ISO 8000,这时候可以看出是一片漆黑,没有细节。

照片b还是相同的参数,ISO提升了接近6挡后,总算看到了一些细节,但在这个高倍率放大的情况下,噪点已经不可控,也能看到已经出现了偏色。

然后看照片c,画面细节明显强于图b,但如果我告诉你:它是图a通过神经网络学习后计算而来,有没有Surprise!?觉得还不够震撼,再看几组样张吧:




身为索尼A7S2和富士XT2,同一组的照片曝光参数一致,每组的第一张图是漆黑一片再后期调亮,第二张则是神经网络学习算法降噪,可以很明显看到,神经网络学习算法让原本相机机内流水线处理后噪点满满的照片,重新恢复到干净清晰的样子(第一组照片是夜间拍摄,照度1lux;第二张是漆黑的室内,照度不到0.05lux)。而且比起我们常见的空域、时域(或两者兼备)降噪算法来说,涂抹感明显更弱,细节表现更好。以比较常用的BM3D为例,作为非盲降噪方案,它需要一个参考噪声值,但这个值若是设小了,最终输出噪声依然会很大,但如果这个值设大了,就会呈现出很明显的涂抹效果。
而神经网络学习的好处就是可以无需噪声参考值,直接计算,同时可以保留高速快门,没有长曝或多帧均值的稳定性问题。所以神经网络学习计算到底是怎样实现的,距离我们还有多远呢?
首先要区分几个概念,第一是图像处理,单单从降噪算法的角度来说就是通过滤波等方式进行降噪,输入输出端都是图像,比如BM3D。
第二是计算机视觉,输入源是视觉数据,可输出三维空间的长短、大小、距离、数量、形状等属性信息,主要用于视频处理。
第三就是近两年开始盛行的神经网络学习。作为机器学习的方式之一,它的输入端可以是任何形式的信号,输出的则是一套关于该信号的模型。对于我们今天的主题:降噪处理来说,工程师可以完全不懂图像,算法也压根不需要理解图像,因为它可以实现单像素级的分类处理。
但神经网络学习的前提是输入大量对比信息(既然是学习,不提供"教材"怎么学?),所以首先是建立"教材"数据库。以我们的案例来看,需要在极度弱光环境下,以1/30秒、1/25秒、1/10秒各拍摄一张严重欠曝的照片,再把快门速度放慢300/250/100倍,各自再拍摄一张长曝光照片作为参考系。不同的场景,不重复地拍摄数千张,直至数据库建立完成。
有了教材,那就可以找老师开始学习了,使用L1 loss和Adam优化器(基于梯度的优化算法,简单高效)进行神经网络训练,输入严重欠曝的原始图,以相应倍率差(比如1/30秒对应300倍,1/10秒对应100倍)长曝光图作为参考系,进行像素级的逐点学习。期间会不定期改变倍率关系,也会裁剪其中512X512像素来进行学习,也会随机翻转、旋转照片来进行数据增强。整个数据库跑4000次全数据集,前2000次学习率为10的-4次方,后2000次降低为10的-5次方。
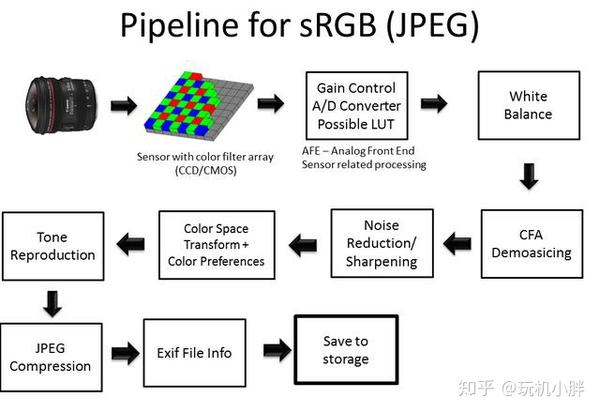
教材有了,老师也有了,现在就需要一套流水线(教学规范)来构建系统了。传统的图像处理在模数转换之后的流水线是:白平衡、解马赛克恢复RGB、降噪锐化、色域转换(主要是sRGB),伽马校正,输出。
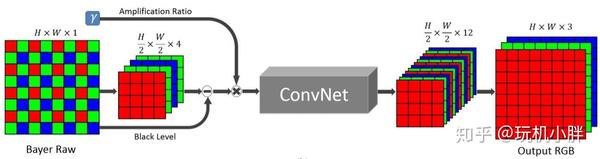
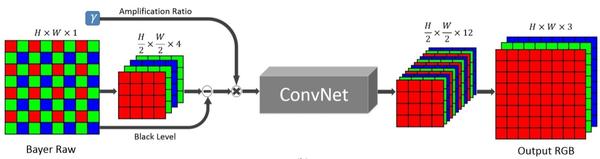
但神经网络学习因为是一对一的像素级,需要另一种与之适配的流水线形式,目前比较好的方式就是全卷积网络(Fully-Convolutional Network),首选架构为U-net(省内存,靠显存堆数据,显卡为Titan X)。第一步是直接在RAW域分离RGBG各通道,原本是长宽16X16的像素矩阵,这时候就变成长宽4X4的4个RGBG图层,然后减去一个黑电平值,再乘以一个放大率(决定最终图像亮度),将乘积丢进神经网络学习得到的模型中,可输出长宽4X4的12个R、G、B、G独立图层,最终还原为16X16的R、G、B三色图层。
最终算出的峰值信噪比达到28.88,结构相似性也有78.7%,下图是神经网络学习降噪和基于原图BM3D降噪的对比:


照度0.5lux,两种方案的降噪差距可以是说一眼便知,BM3D可能同时放大噪点和涂抹过渡的问题也有所呈现,但依然可以看到,神经网络学习后的降噪效果,在100%放大时细节还原还是不能做到最好,差了近20%的结构相似度不容忽视。
目前来看,相同结构传感器之间使用同一套算法模型理论上没有太大问题,比如同事拜耳阵列的iPhone 6S就可以利用A7S2的训练模型,如下图:


1/20秒,ISO 400,可以看到传统的后期增亮会带来非常明显的噪声,但通过神经网络学习模型计算后,噪声控制更出色且不存在色彩漂移。
应用于极弱光环境的图像处理神经网络学习还处于初级阶段,可应用于学习的现有数据库很少,有的数据库没有使用真实拍摄场景,仅仅是人为添加高斯噪声来进行降噪验证。RENOIR的图像数据虽然基于现实,但有很多对齐不整,不少参考照片的设置也有问题。谷歌HDR+和DND的数据虽多但不是针对极弱光环境……所以才需要自行拍摄训练数据库。但这并不是终端用户需要操心的事情,上游厂商在意识到神经网络学习的意义之后自然会建立相应的数据库,所以这才有了本文的标题:算法代表摄影的未来。
当然,除此之外还要解决HDR色调映射、亮度放大率内置甚至自动化(类似自动ISO)、加快处理速度(A7S2需要0.38秒才能完成一次计算,实用性较差)……但还是那句话,机器学习甚至深度学习对整个图像处理领域带来了前所未有的新空间,也必然是各大影像器材品牌未来最重要的发力点之一。
来源:知乎 www.zhihu.com
作者:玩机小胖
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载
没有评论:
发表评论