
这篇文章主要是介绍live script和table相关函数的使用, 还不涉及到机器学习.
记者: live script+table给你什么样的感觉? 相比比较流行的python数据工具链呢?
菡姐: live script + table给我的感觉呢?
感觉比jupyter notebook + pandas好多了!
MATLAB有workspace, jupyter notebook没有, 就好比汽车没有码速表一样!
spyder也有workspace, 但是它不能显示所有的数据类型, 而且数据量一大, 容易卡死.
哎呦, 我超喜欢玩MATLAB的!
我之前写过:
菡姐:MATLAB的数据分析工具链菡姐:使用MATLAB数据分析工具链进行实战: 看电影真的是男女有别现在就用上面提到的数据分析工具链进行实战.
使用的例子是《利用Python进行数据分析》 麦金尼 (Wes McKinney), 唐学韬, 等【摘要 书评 试读】图书 里面第二章的第三个例子.
(没看过这本书的读者不需要买这本书, 除非你想用python进行数据分析)
之所以使用这个例子, 是因为:
1 我对这个例子比较熟悉, 之前学pandas时, 好好研究过这个例子.
2 网上能够下载到数据.
3 可以做对照, 确保我用MATLAB做出的结果与用pandas做出的结果是一致的, 防止出错.
这个例子所需要的数据可以在这下载:
wesm/pydata-bookOK, 正式开始了.
文章比较长, 我先说一下大概的内容吧:
1 分析了一下英文教材里面的常见名的历史流行度, 发现这些名字以前很流行, 现在已经冷门了.
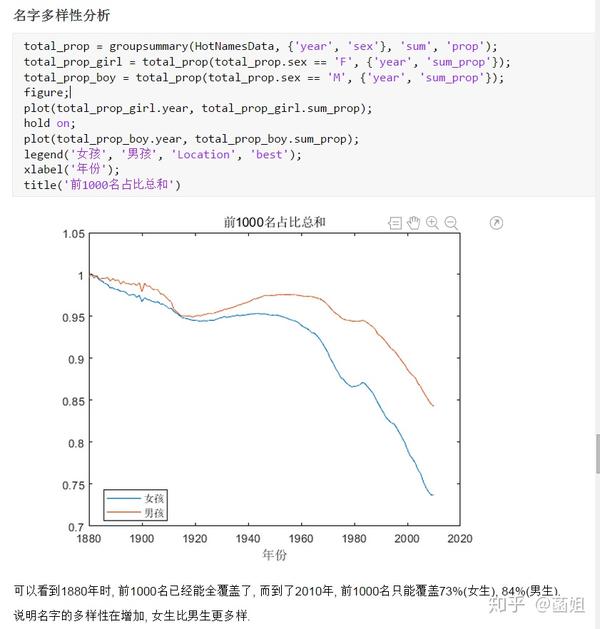
2 名字多样性逐渐提高了, 而且女孩的多样性明显高于男孩的.
3 名字的尾字母的流行度也在发生变化.
4 发现了一组"变性"的名字!!!
先给live script的截图, 方便读者直接看到运行结果
再给转化为普通script的程序, 方便读者在自己电脑上运行.


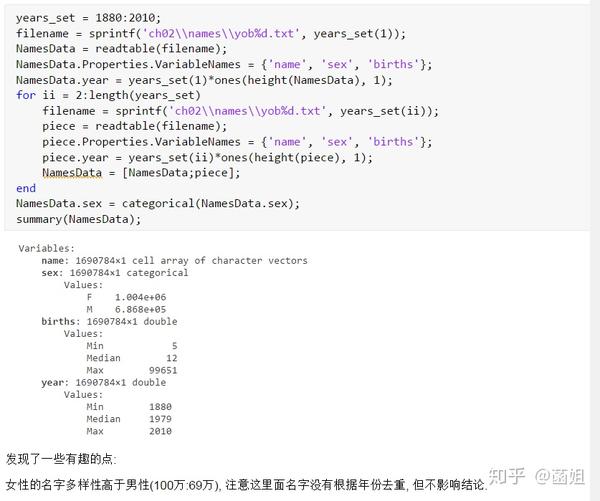
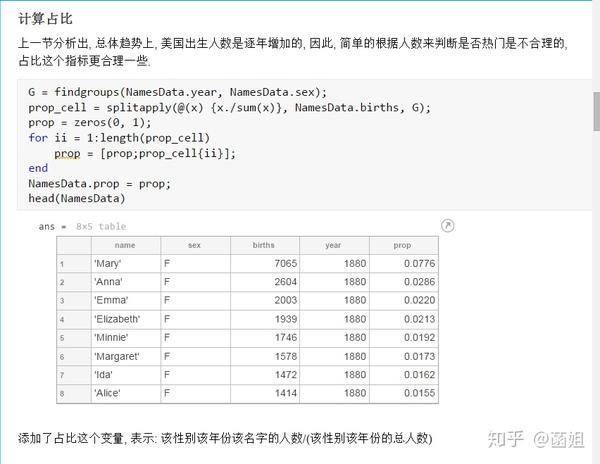
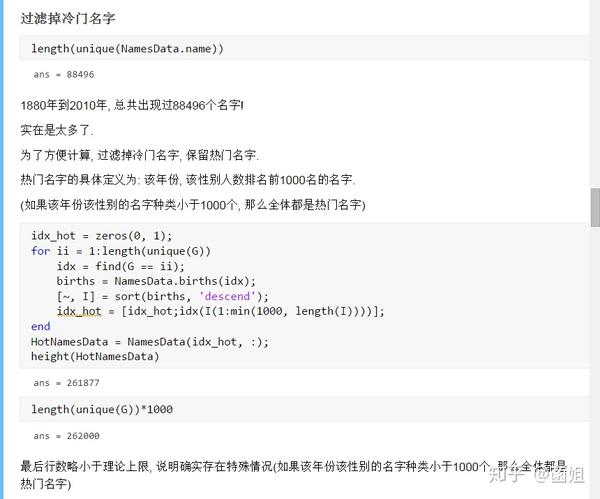
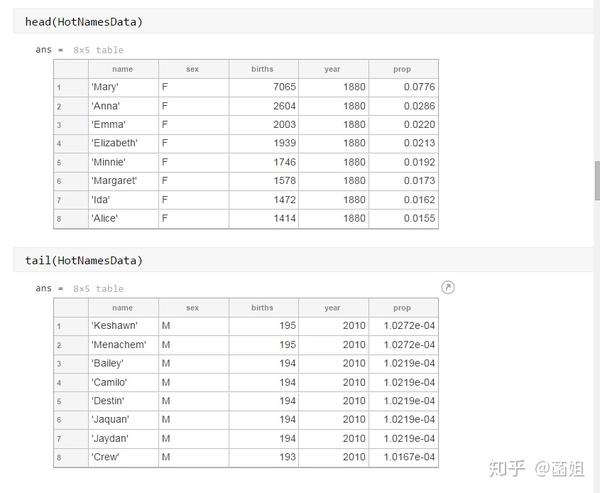
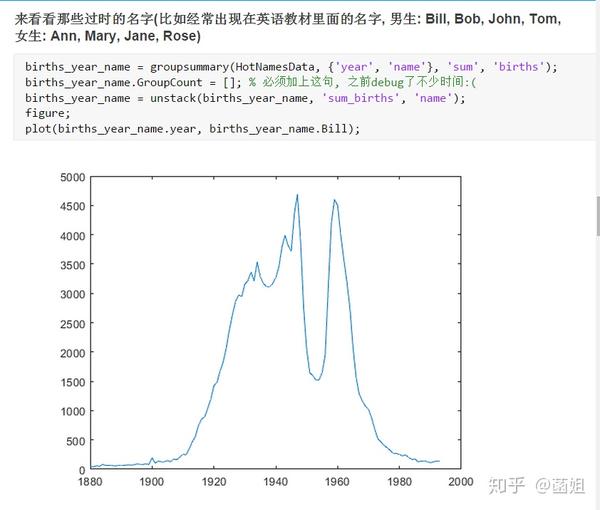
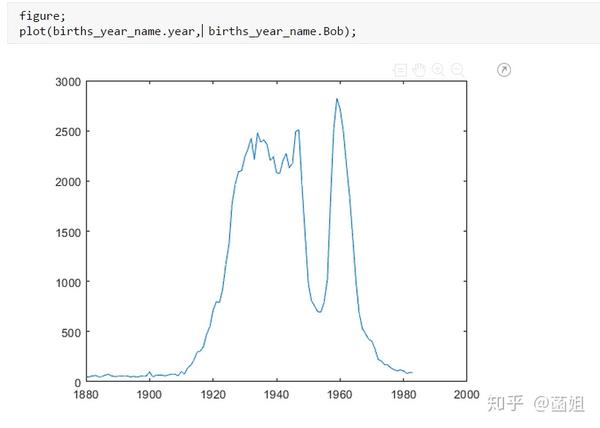
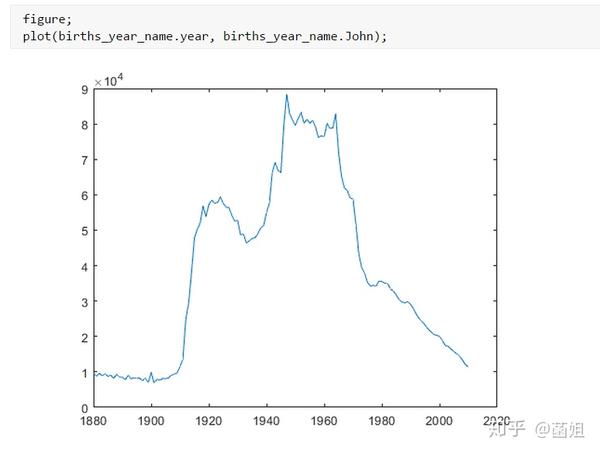
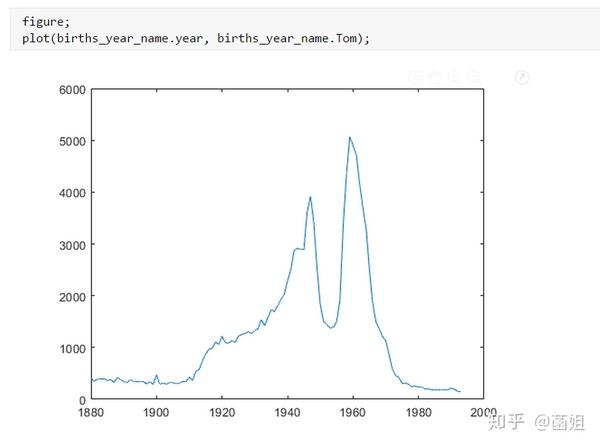
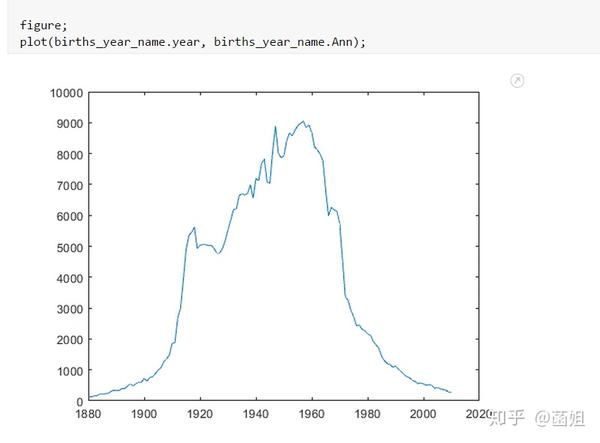
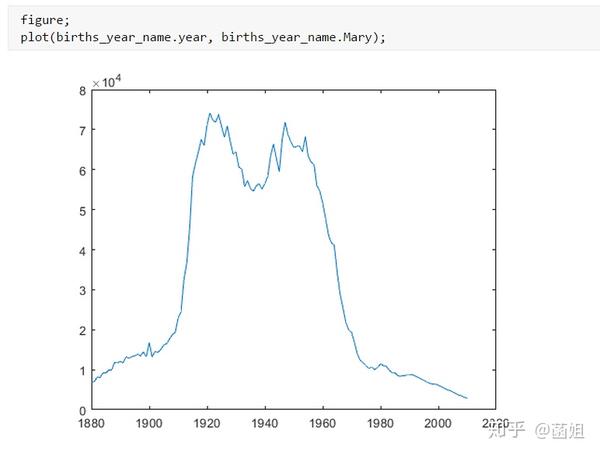
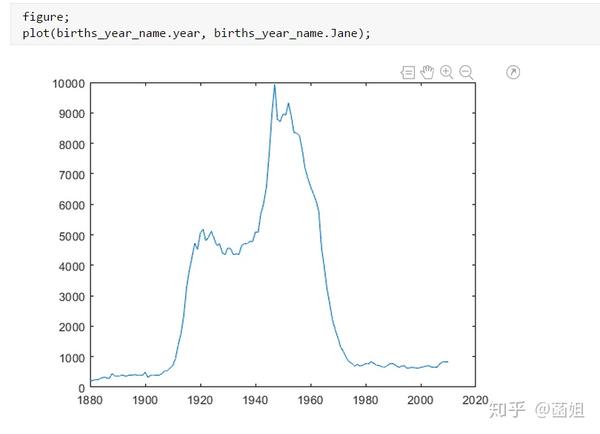
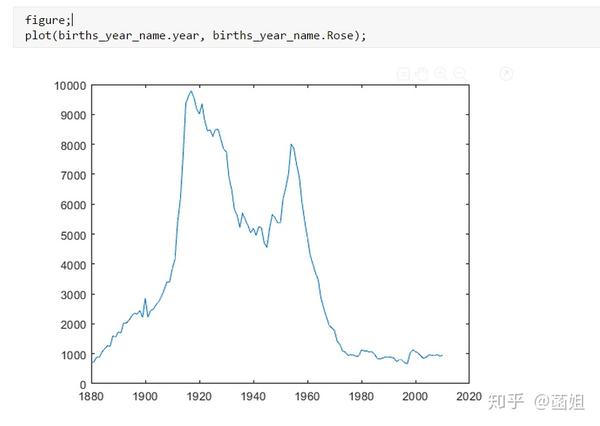

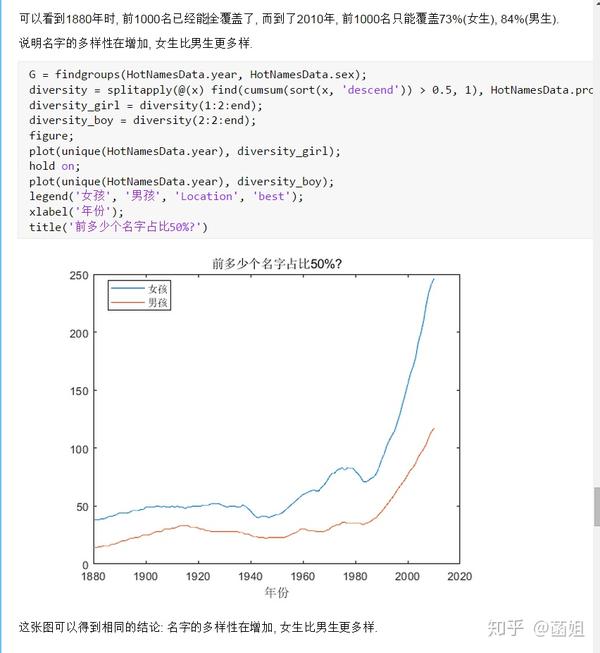
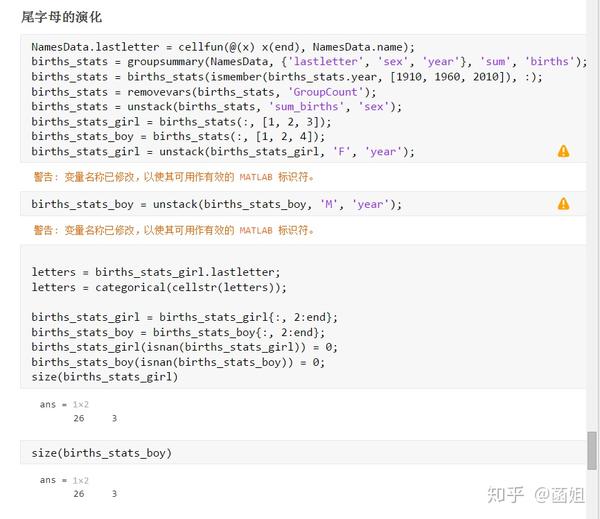
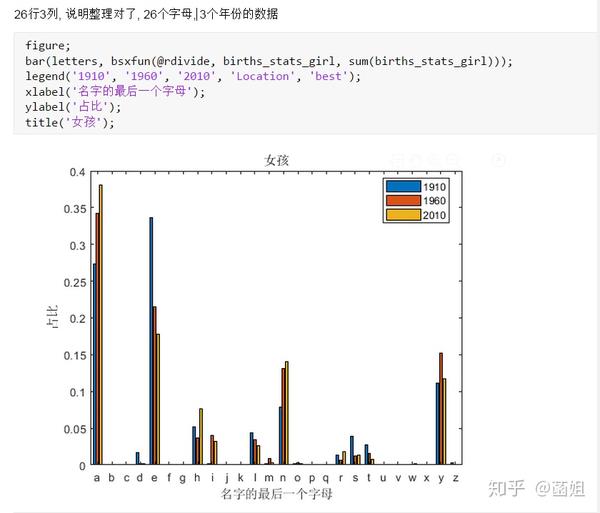
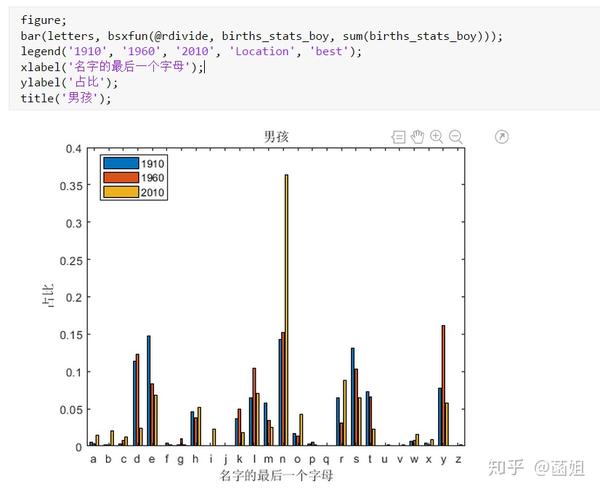

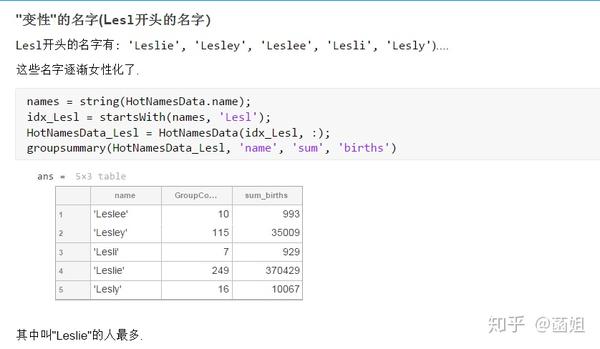
数据下载完后, 可以直接运行了, 使用R2018a以上的版本(groupsummary是R2018a的新函数, 如果改成findgroup+splitapply的话, 更老一些的版本应该也能运行).
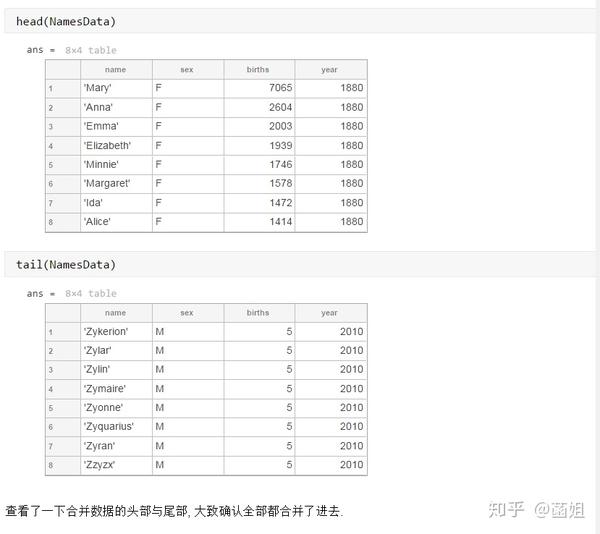
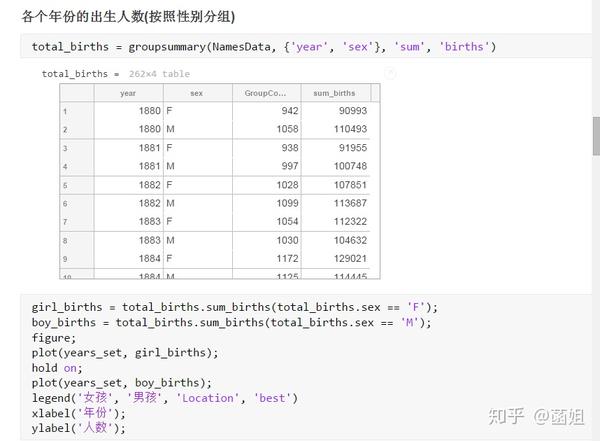
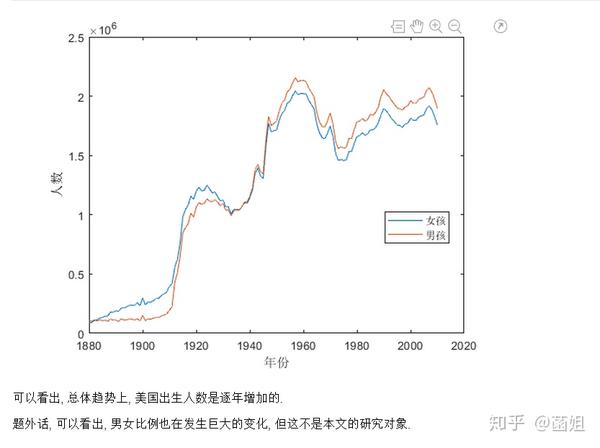
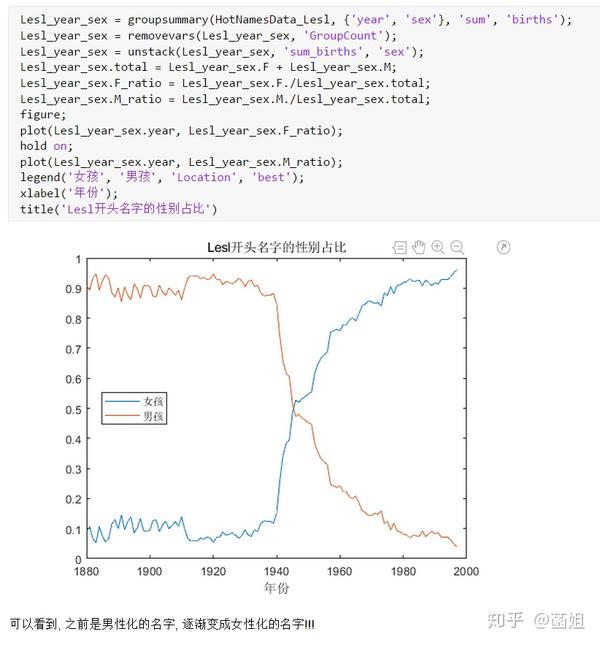
%% 美国婴儿名字分析-不要再用英语教材里面的英文名了!!! %% 合并数据(1880年至2010年) % 一个文件只存一年的婴儿名字的统计数据. % % 如图所示: % % % % 每个文件里面的格式是这样的: % % % % 第一列是婴儿的名字, 第二列是婴儿的性别, 第三列是那一年该性别, 起该名字的婴儿的数量. %% years_set = 1880:2010; filename = sprintf('ch02\\names\\yob%d.txt', years_set(1)); NamesData = readtable(filename); NamesData.Properties.VariableNames = {'name', 'sex', 'births'}; NamesData.year = years_set(1)*ones(height(NamesData), 1); for ii = 2:length(years_set) filename = sprintf('ch02\\names\\yob%d.txt', years_set(ii)); piece = readtable(filename); piece.Properties.VariableNames = {'name', 'sex', 'births'}; piece.year = years_set(ii)*ones(height(piece), 1); NamesData = [NamesData;piece]; end NamesData.sex = categorical(NamesData.sex); summary(NamesData); %% % 发现了一些有趣的点: % % 女性的名字多样性高于男性(100万:69万), 注意这里面名字没有根据年份去重, 但不影响结论. head(NamesData) tail(NamesData) %% % 查看了一下合并数据的头部与尾部, 大致确认全部都合并了进去. %% 各个年份的出生人数(按照性别分组) %% total_births = groupsummary(NamesData, {'year', 'sex'}, 'sum', 'births') girl_births = total_births.sum_births(total_births.sex == 'F'); boy_births = total_births.sum_births(total_births.sex == 'M'); figure; plot(years_set, girl_births); hold on; plot(years_set, boy_births); legend('女孩', '男孩', 'Location', 'best') xlabel('年份'); ylabel('人数'); %% % 可以看出, 总体趋势上, 美国出生人数是逐年增加的. % % 题外话, 可以看出, 男女比例也在发生巨大的变化, 但这不是本文的研究对象. %% 计算占比 % 上一节分析出, 总体趋势上, 美国出生人数是逐年增加的, 因此, 简单的根据人数来判断是否热门是不合理的, 占比这个指标更合理一些. %% G = findgroups(NamesData.year, NamesData.sex); prop_cell = splitapply(@(x) {x./sum(x)}, NamesData.births, G); prop = zeros(0, 1); for ii = 1:length(prop_cell) prop = [prop;prop_cell{ii}]; end NamesData.prop = prop; head(NamesData) %% % 添加了占比这个变量, 表示: 该性别该年份该名字的人数/(该性别该年份的总人数) %% 过滤掉冷门名字 %% length(unique(NamesData.name)) %% % 1880年到2010年, 总共出现过88496个名字! % % 实在是太多了. % % 为了方便计算, 过滤掉冷门名字, 保留热门名字. % % 热门名字的具体定义为: 该年份, 该性别人数排名前1000名的名字. % % (如果该年份该性别的名字种类小于1000个, 那么全体都是热门名字) idx_hot = zeros(0, 1); for ii = 1:length(unique(G)) idx = find(G == ii); births = NamesData.births(idx); [~, I] = sort(births, 'descend'); idx_hot = [idx_hot;idx(I(1:min(1000, length(I))))]; end HotNamesData = NamesData(idx_hot, :); height(HotNamesData) length(unique(G))*1000 %% % 最后行数略小于理论上限, 说明确实存在特殊情况(如果该年份该性别的名字种类小于1000个, 那么全体都是热门名字) head(HotNamesData) tail(HotNamesData) %% 来看看那些过时的名字(比如经常出现在英语教材里面的名字, 男生: Bill, Bob, John, Tom, 女生: Ann, Mary, Jane, Rose) %% births_year_name = groupsummary(HotNamesData, {'year', 'name'}, 'sum', 'births'); births_year_name.GroupCount = []; % 必须加上这句, 之前debug了不少时间:( births_year_name = unstack(births_year_name, 'sum_births', 'name'); figure; plot(births_year_name.year, births_year_name.Bill); figure; plot(births_year_name.year, births_year_name.Bob); figure; plot(births_year_name.year, births_year_name.John); figure; plot(births_year_name.year, births_year_name.Tom); figure; plot(births_year_name.year, births_year_name.Ann); figure; plot(births_year_name.year, births_year_name.Mary); figure; plot(births_year_name.year, births_year_name.Jane); figure; plot(births_year_name.year, births_year_name.Rose); %% % 可以看出, 很多经常出现在我们英语教材里面的英文名已经过时了 % % 所以, 给自己起英文名的时候, 尽量规避这些名字, 要不然美国人想: 这年轻人怎么起了个爷爷奶奶级的名字? %% 名字多样性分析 %% total_prop = groupsummary(HotNamesData, {'year', 'sex'}, 'sum', 'prop'); total_prop_girl = total_prop(total_prop.sex == 'F', {'year', 'sum_prop'}); total_prop_boy = total_prop(total_prop.sex == 'M', {'year', 'sum_prop'}); figure; plot(total_prop_girl.year, total_prop_girl.sum_prop); hold on; plot(total_prop_boy.year, total_prop_boy.sum_prop); legend('女孩', '男孩', 'Location', 'best'); xlabel('年份'); title('前1000名占比总和') %% % 可以看到1880年时, 前1000名已经能全覆盖了, 而到了2010年, 前1000名只能覆盖73%(女生), 84%(男生). % % 说明名字的多样性在增加, 女生比男生更多样. G = findgroups(HotNamesData.year, HotNamesData.sex); diversity = splitapply(@(x) find(cumsum(sort(x, 'descend')) > 0.5, 1), HotNamesData.prop, G); diversity_girl = diversity(1:2:end); diversity_boy = diversity(2:2:end); figure; plot(unique(HotNamesData.year), diversity_girl); hold on; plot(unique(HotNamesData.year), diversity_boy); legend('女孩', '男孩', 'Location', 'best'); xlabel('年份'); title('前多少个名字占比50%?') %% % 这张图可以得到相同的结论: 名字的多样性在增加, 女生比男生更多样. %% 尾字母的演化 %% NamesData.lastletter = cellfun(@(x) x(end), NamesData.name); births_stats = groupsummary(NamesData, {'lastletter', 'sex', 'year'}, 'sum', 'births'); births_stats = births_stats(ismember(births_stats.year, [1910, 1960, 2010]), :); births_stats = removevars(births_stats, 'GroupCount'); births_stats = unstack(births_stats, 'sum_births', 'sex'); births_stats_girl = births_stats(:, [1, 2, 3]); births_stats_boy = births_stats(:, [1, 2, 4]); births_stats_girl = unstack(births_stats_girl, 'F', 'year'); births_stats_boy = unstack(births_stats_boy, 'M', 'year'); letters = births_stats_girl.lastletter; letters = categorical(cellstr(letters)); births_stats_girl = births_stats_girl{:, 2:end}; births_stats_boy = births_stats_boy{:, 2:end}; births_stats_girl(isnan(births_stats_girl)) = 0; births_stats_boy(isnan(births_stats_boy)) = 0; size(births_stats_girl) size(births_stats_boy) %% % 26行3列, 说明整理对了, 26个字母, 3个年份的数据 figure; bar(letters, bsxfun(@rdivide, births_stats_girl, sum(births_stats_girl))); legend('1910', '1960', '2010', 'Location', 'best'); xlabel('名字的最后一个字母'); ylabel('占比'); title('女孩'); figure; bar(letters, bsxfun(@rdivide, births_stats_boy, sum(births_stats_boy))); legend('1910', '1960', '2010', 'Location', 'best'); xlabel('名字的最后一个字母'); ylabel('占比'); title('男孩'); %% % 可以发现: % % 女孩名字的最后一个字母, 'a'越来越多了, 'e'越来越少了. % % 男孩名字的最后一个字母, 'n'越来越多了. %% "变性"的名字(L|esl开头的名字)| % L|esl开头的名字有: 'Leslie', 'Lesley', 'Leslee', 'Lesli', 'Lesly'|).... % % 这些名字逐渐女性化了. %% names = string(HotNamesData.name); idx_Lesl = startsWith(names, 'Lesl'); HotNamesData_Lesl = HotNamesData(idx_Lesl, :); groupsummary(HotNamesData_Lesl, 'name', 'sum', 'births') %% % 其中叫"Leslie"的人最多. Lesl_year_sex = groupsummary(HotNamesData_Lesl, {'year', 'sex'}, 'sum', 'births'); Lesl_year_sex = removevars(Lesl_year_sex, 'GroupCount'); Lesl_year_sex = unstack(Lesl_year_sex, 'sum_births', 'sex'); Lesl_year_sex.total = Lesl_year_sex.F + Lesl_year_sex.M; Lesl_year_sex.F_ratio = Lesl_year_sex.F./Lesl_year_sex.total; Lesl_year_sex.M_ratio = Lesl_year_sex.M./Lesl_year_sex.total; figure; plot(Lesl_year_sex.year, Lesl_year_sex.F_ratio); hold on; plot(Lesl_year_sex.year, Lesl_year_sex.M_ratio); legend('女孩', '男孩', 'Location', 'best'); xlabel('年份'); title('Lesl开头名字的性别占比') %% % 可以看到, 之前是男性化的名字, 逐渐变成女性化的名字!!! % % 如果有帮助的话, 赞赏一下吧. 花了一个下午做出来的.
----更新分割线--------------------------------------------------------------------------
有人对top100的名字有兴趣, 我将2010年的流行名字进行了提取,并且画成了词云.
女孩名字top100:

男孩名字top100:
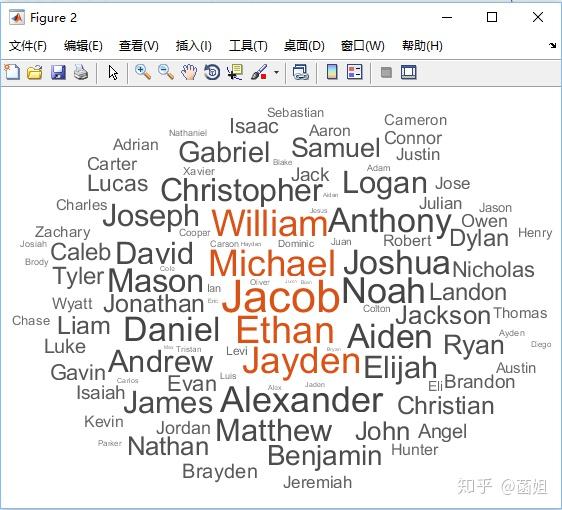
代码如下, 在上面代码的下面补充上即可:
%% 女孩名字top100, 男孩名字top100 HotNamesData_2010 = HotNamesData(HotNamesData.year == 2010, :); HotNamesData_2010_girl = HotNamesData_2010(HotNamesData_2010.sex == 'F', :); HotNamesData_2010_boy = HotNamesData_2010(HotNamesData_2010.sex == 'M', :); [~, idx_girl] = sort(HotNamesData_2010_girl.births, 'descend'); top100_2010_girl = HotNamesData_2010_girl(idx_girl(1:100), :); [~, idx_boy] = sort(HotNamesData_2010_boy.births, 'descend'); top100_2010_boy = HotNamesData_2010_boy(idx_boy(1:100), :); figure; wordcloud(top100_2010_girl.name, top100_2010_girl.births); figure; wordcloud(top100_2010_boy.name, top100_2010_boy.births); 来源:知乎 www.zhihu.com
作者:知乎用户(登录查看详情)
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载
没有评论:
发表评论