
选自arxiv,作者:乔明达,机器之心编译。
不久之前,ICML 2018 的接收论文列表放出,机器之心也开始报道这一学术会议上的顶级研究成果。在接收论文列表中,我们发现了北大、清华、复旦、腾讯、百度等来自中国学术界、产业界的论文(之后我们会持续为大家编译介绍 ICML 2018 论文)。在本文中,我们编译介绍了清华特奖得主、交叉信息院 2014 级本科生乔明达一人署名的论文《Do Outliers Ruin Collaboration?》。同时,也欢迎机器之心读者为我们推荐更多优秀的 ICML 2018 论文。
论文接收列表:https://icml.cc/Conferences/2018/AcceptedPapersInitial
考虑以下现实场景:我们想基于从不同用户收集的标记样本来训练语音识别模型。对于这一特定应用,所有用户的高平均准确率还远不能令人满意:即使是应用在 99.9% 的数据上都实现准确预测的模型,对于那比例很小但不可忽略的 0.1 % 的用户来说仍然可能出现严重错误。更理想的目标是找到对每个用户都准确的个性化语音识别解决方案。
实现这一目标有两个主要挑战,第一个挑战是用户异构性:一个专门为具有特色口音的用户训练的模型对来自另一个地区的用户可能无效。所以一个成功的学习算法应该具有适应性:要从具有非典型数据分布的用户收集更多的样本。同样重要的是,一小部分用户是恶意的(例如,他们受到竞争公司的控制);这些用户意图误导语音识别模型产生不准确甚至可笑的输出。
基于这些实际问题,本文提出了一种鲁棒协作学习模型(Robust Collaborative Learning model),并从理论角度研究了在具有不可信协作者的情况下学习的复杂性。在该模型中,一个学习算法与 n 个不同的用户交互,每个用户与一个数据分布 D_i 相关联。如上所述,理想的成功学习算法应当为不同的分布找到个性化分类器 f_1、f_2……f_n,使得以下公式:
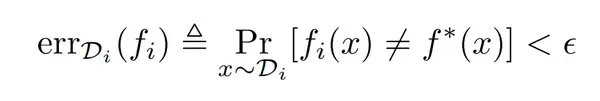
对于每个 I∈[ n ] 都成立。其中 f*(x)表示样本 x 的真实标签。使情况变得复杂的是,该算法只能经由用户与数据分布交互,而每个用户可能是诚信用户,也可能是恶意用户。诚信用户总是向学习算法提供从其分布中抽取的独立样本以及正确的标签,而从恶意用户收集的标签样本则是任意的。
在存在恶意用户的情况下,显然不可能为每个单独的分布学习准确的分类器:恶意用户可能不会提供关于其数据分布的信息。因此,更现实的目标是满足所有诚信用户,即学习 n 个分类器 f_1、f_2……f_n,使得 errDi(fi)< ǫ适用于每个诚信用户 i。
我们可以忽略一个先验知识,即诚信用户的样本由相同函数标记,并且为 n 个用户运行相同学习算法的 n 个独立副本。这种直接的方法显然需要至少 n 倍于学习单个数据分布所需的样本。按照 Blum 等人使用的术语 [4],作者认为这种算法导致Ω(n)采样复杂度计算开销 (sample complexity overhead)。计算开销用于衡量学习在多大程度上受益于不同当事方之间的协作和信息共享。Blum 等人 [4] 提出了一种在所有用户都是诚信用户,即η= 0 的情况下,实现 O(ln n)开销的学习算法。然后,研究者对回答以下问题产生了兴趣:当η> 0,至少当η足够小时,我们还能获得次线性开销吗?换句话说,恶意用户是否会破坏协作的效率?
结论:1. 信息理论上来说是鲁棒的;2. 计算上,异常值可能会破坏协作。
3 一种迭代学习算法
在这部分里,研究者展示了一种迭代(ǫ, δ, η)-学习算法,达到了 O(ηn+ln n)的计算开销(n=O(d))。这里 n表示用户数量,d 表示假设类 F 的 VC-维。由于 F 可以是很大甚至为无穷大的值,作者假设算法通过一个 oracle O_F 访问 F,给定一个标记样本的集合 S={(x_i,y_i)},算法将返回一个分类器 f∈F 从而 f(x_i)=y_i 对所有数据对(x_i , y_i)∈ S 都成立;或者返回⊥,如果 F 不包含任何一致函数。算法通过 n 个样本的数据库 O_1,O_2,...,O_n 和潜在的数据分布 D_1,D_2,...,D_n 进行交互,其中最多有η比例的样本是恶意的。
3.1 算法
本文提出的算法在算法 1 到算法 3 中给出了形式化的描述。主要的算法是按回合迭代执行的,并在回合 r 的起始处保持一个活跃用户索引的集合 G_r,即那些目前未曾达到ǫ-accurate 分类器的用户。当恶意样本的最大可能数量 ⌊ηn⌋ 低于|G_r|/10 时,算法将启动一个子程序 Candidate 以寻找候选分类器 hat f_r。然后,算法 1 调用验证流程 Test 来检查 hat f_r 是否对 G_r 的每个用户都能做出准确的预测(相对于准确率阈值ǫ)。如果是,该算法将用户 i 的输出标记为 hat f_r;否则,用户 i 保留在下一回合的集合 G_r+1 中。当恶意样本的比例达到 1/10 时,算法独立地为余下的用户学习:对每个活跃用户,它从其数据库提取样本,并输出与其数据一致的任意分类器。


3.2 对子程序的分析
子程序 Candidate(算法 2)是本文算法采样效率的关键,它允许我们学习一个同时对常数比例的活跃用户准确的候选分类器,并仅使用了样本的将近线性的数量(相对于参数|G|和 d)。子程序 Test(算法 3)进一步检查了该学习到的分类器是否对于每个活跃用户足够准确。这让我们可以决定某个用户在下一次迭代中是否应该被保留在活跃用户中。本节将对这两个子程序进行分析。
4 计算开销的下边界
在这一部分,作者表明当 n=Θ(d) 时,Ω(ηn + ln n) 的计算开销是不可避免的,因此,由算法 1 达到的计算开销是最优的并达到一个常数因子(当用户数量和假设类的复杂度相当时)。
5 讨论:存在计算效率高的算法?
虽然算法 1 被证明在某些情况下能达到最优的样本复杂度开销,但是当有大量用户时,该算法的计算效率低下,且实际使用有限。具体来说,候选子程序对于所有大于等于 9/10|G|的用户子集执行穷举搜索法,因此可能会指数级次数地调用 oracle O_F。相比之下,朴素方法分别学习不同的用户,因此即使有Ω(n) 的开销,但它只会调用 n 次 oracle O_F。当然,有人可能会疑惑是否能找到一个计算效率高的学习算法同时解决上述两种开销?但作者认为,这种算法是不存在的。
猜想 5.1:对于所有α > 1 和β < 1,当η = Ω(n^α) 时,没有学习算法能多次调用多项式 oracle O_F 实现 O(n^β ) 开销。
换句话说,当有非常多的恶意用户时,任何高效的学习算法都能产生近线性的开销。作者注意到有必要假设α > −1,因为当最大可能恶意用户数ηn 为常数时,学习算法可以在多项式时间内枚举恶意用户的子集,从而有效地实现最优开销。证明或证伪猜想 5.1 将大大加深我们对协作学习中任意异常值影响的理解。
本文提出的样本效率学习算法的关键是识别一大组用户的候选子程序,例如一些分类器 f hat ∈ F 与它们的标注样本保持一致性。引理 3.1 进一步保证了 f hat 至少对于一半的用户是 ε-accurate。这使得我们能够满足 O(ln n) 迭代中几乎所有的用户,并产生了开销中的 ln n 项。
作者注意到,找到一组有一致数据集的用户可以推广到搜索无向图中较大团的问题:对于节点标注为 1 到 n 的无向图,我们构建用户的 oracles O_1 到 O_n,其中如果图中没有(i,j),O_i 和 O_j 会在相同数据上产生冲突标签。此外,当且仅当一组用户在对应的图中形成一个团,它们才拥有一致的数据集。
不幸的是,Zuckerman[13] 证明了即使无向图中已知包含一个大小为Ω(n)^5 的隐藏团,为任意的β<1 找到一个大小为Ω(n^(1−β) ) 的团仍然是 NP-hard 的。这意味着,使用算法 1 的方法,一个计算高效的算法在每一次迭代中只能为最多 O(n^(1−β) ) 个用户寻找准确的分类器。因此,为了满足所有 n 个用户的需求,需要Ω(n^β ) 次迭代。所以该算法的计算开销为Ω(n^β )。
论文:Do Outliers Ruin Collaboration?

论文地址:https://arxiv.org/pdf/1805.04720.pdf
我们在本文中考虑了从 n 个不同的数据源学习二值分类器的问题,其中最多有η比例的样本是恶意的(adversarial)。计算开销被定义为在该设置中的学习过程以及在单个数据分布上学习相同假设类的采样复杂度之间的比率。我们在文中展示了一种算法,其能达到 O(ηn+lnn)的计算开销,在最坏情况下是最优的。我们还讨论了设计小计算开销的高效学习算法的潜在挑战。

来源:知乎 www.zhihu.com
作者:机器之心
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载
没有评论:
发表评论