思路清奇的笔试题?
2018 年,创新工场AI工程院举办的 DeeCamp 人工智能训练营打算培养 300 名大学生。这是 DeeCamp 的第二期。报名异常踊跃,全球近 7000 名学生申请。
6 月 8 日和 9 日两天,报名的同学接受了在线笔试。笔试还没结束就出现了各种热闹事儿。比如,有的同学想通过运行考题中的代码来寻找答案,没想到,简单的几行代码很快耗尽了电脑资源,有的电脑竟直接崩溃!笔试结束,微信群里热闹非常。同学们兴致勃勃地讨论笔试题目。有的题目,大家讨论了几小时还热情不减。有同学连连感叹,这题目真是思路清奇!
什么样的在线笔试题,才能让电脑崩溃,才能给人留下思路清奇的印象呢?
设计 AI 入门级开卷笔试题的挑战
设计在线笔试题,本来就难。设计 DeeCamp 的在线笔试题,尤其有挑战。
在线笔试本身就是半开卷的性质。想要所有同学都严格遵守闭卷规定,极难。好多公司为了防止所谓在线笔试"作弊",尝试过各种好玩的招数,比如要求开着摄像头答题,其实大多是掩耳盗铃。真正好的在线笔试题,应该是即便开卷,答题者也需要动脑筋思考的题目。
记得以前 Google 使用的在线笔试题,大多是偏重算法的题目,可以看做是简化版的 ACM。这的确是一种设计开卷笔试题的思路,因为很多经典算法问题,都可以被包装到一个很具体的场景中。学生考试时,即便用搜索引擎去查找这个具体场景,只要以前没考过类似的题目,就很难搜到正确答案。最起码,学生需要有一定的算法知识,能够将遇到的问题抽象成特定的算法模式,然后再去搜索对应的解决方案。
但是,回到 DeeCamp,如果按照简化版 ACM 的思路,就不能满足要求了。因为 DeeCamp 希望招聘的学生标准与 Google 要招聘的学生标准有很大不同。Google 是一家公司,想招进来的是最聪明的、编程能力和算法能力最强的学生。DeeCamp 是一个训练营,本来就是以培训为目的,当然不能把入门考试的要求设得太高。
DeeCamp 想招进来的是这样的学生:聪明、知识面广、动手能力强、有不错的数学和编程基础,了解机器学习特别是深度学习的基本概念。因为 DeeCamp 强调AI人才培养,入门考试当然不会要求每个学生都能熟练掌握 CNN、RNN 之类的网络细节,或者特别擅长解决算法难题。
也就是说,我们创新工场 AI 工程院这个命题小组,要设计的是一套 AI 入门级的开卷笔试题,无论是数学、编程、算法还是 AI,都只适合考察最基本的知识技能,而不适合强调题目的专深。同时,这套题还需要在题目的趣味性、灵活度等方面下功夫,最好有一些平常很少见到的新场景,以考察同学们在解决新问题时的实战技能。更重要的,这些题目需要在学生开卷答题的情况下,还能有足够的区分度。
各种要求的叠加下,并没有完美的解决方案。既不能完美防作弊,也没法在难度、知识点、趣味性等方面达到完美均衡。我们这个命题小组只是尽力而为。
如何考察基本概念?
考察基本概念的题目都是送分题,但送分也不能太直接、太坦白。也就是说,对那些没学好基本概念的同学,开卷考试时,好歹也要让他们在搜索引擎里费些周折,不能太直接查到答案。比如下面这道原题:
下面有关计算机基本原理的说法中,正确的一项是:
(A) 堆栈(stack)在内存中总是由高地址向低地址方向增长的。
(B) 发生函数调用时,函数的参数总是通过压入堆栈(stack)的方式来传递的。
(C) 在 64 位计算机上,Python3 代码中的 int 类型可以表示的最大数值是 2^64-1。
(D) 在任何计算机上,Python3 代码中的 float 类型都没有办法直接表示 [0,1] 区间内的所有实数。
每个选项,都涉及计算机基本原理或编程语言的某种基本知识。如果没学好计算机原理,或没掌握程序设计的一些本质问题,即便开卷,大概也很难搞清楚该如何用搜索引擎快速查找答案吧。
另外,既然是开卷,选项(C)和选项(D)就没有回避 Python3 这样的具体编程语言的具体版本。因为即便不懂 Python 编程,也至少能搜索到,Python3 里面的整数类型取值范围是什么。或者,对于选项(D),只要从编程语言的本质出发,明白计算机里的浮点类型只是一种用离散方式近似表达实数区间的方法,就可以知道,Python 里的 float 是不可能涵盖 [0,1] 区间内的所有实数的。
类似的,有关深度学习基本概念和基本框架的选择题是这个样子的:
有关深度神经网络的训练(Training)和推断(Inference),以下说法中不正确的是:
(A) 将数据分组部署在不同 GPU 上进行训练能提高深度神经网络的训练速度。
(B) TensorFlow 使用 GPU 训练好的模型,在执行推断任务时,也必须在 GPU 上运行。
(C) 将模型中的浮点数精度降低,例如使用 float16 代替 float32,可以压缩训练好的模型的大小。
(D) GPU 所配置的显存的大小,对于在该 GPU 上训练的深度神经网络的复杂度、训练数据的批次规模等,都是一个无法忽视的影响因素。
总结起来,这次笔试里的基本概念题,大概涵盖了以下几个方面的基本知识:
- 基本数学知识,比如函数和矩阵运算。
- 计算机原理和编程基础知识,比如堆栈、数据类型。
- 机器学习的基础知识,比如 Precision 和 Recall。
- 深度学习的基础知识,比如表示学习的概念。
- TensorFlow 的基本概念,比如 Variable 和 placeholder 的区别。
补充一下,有同学问到,概念题里,有一个有关 TensorFlow 的题目,提到了 TensorFlow 的符号执行(Symbolic Execution)和计算图优化(Computational Graph Optimization),相关的参考资料到底在那里?
其实,TensorFlow 白皮书里,"5.1 Common Subexpression Elimination"就是关于计算图优化的一个举例说明。有关符号执行对于计算图优化的作用,MXnet 文档里有一篇特别浅显的讲解:Programming Models for Deep Learning。其中对流行的框架做了一个归类:"Examples of imperative style deep learning libraries include Torch, Chainer and Minerva. While the examples of symbolic style deep learning libraries include Theano, CGT and Tensorflow."
如何考察 AI 相关的数学知识?
比如,卷积是深度学习常用的数学知识,一些熟悉 CNN 的同学可能没有仔细想过卷积的数学含义到底是什么?卷积在 CNN 中常以二维数学形式出现,那么,卷积的N维表达式是什么?一维卷积又是如何计算的?CNN 中的卷积,和语音信号处理中的卷积,数字图像处理中的卷积,是如何联系在一起的?
知乎有一个很好的问题,"如何通俗易懂地解释卷积?"这个问题下面,有好几个特别有趣的答案,大家可以参考。
当然,实际笔试题里,关于卷积的问题特别简单:
一维离散卷积的定义是![(a*v)[n]=\sum_{m=-\infty}^{\infty}{a[m]v[n-m]}](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_vd3F8N6zHi5bcMTRrcEXQsXyFxoxIKbdY-HuvRkEGuatNKigmp5hfIWhHOAD89rkV0wpwKGaIoOZr6IsdCEjl7YTMLykeVvc4e43Dl_jt-2LAIPFd1vBQaLgwklARt0KbGrf4U5kyjWQK--ZOWtM6j-N7_oE6YvvxTdwqAktc4F0s7rmfx81lo97KjjMWILX6j3hgpLQpQ=s0-d)
给定一维数组 a = [1, 2, 3], v = [4, 5, 6],它们的离散卷积结果是?
熟悉卷积计算的同学,可以很快写出答案。因为是开卷,就算搞不清这么简单的公式,如果能想起来手头有很多现成的工具可用,比如用 numpy 的卷积计算函数实际算一下
numpy.convolve(a, v) 这种愿意学习、勤于动手的学生也很不错!
类似的,真题中,还有一些结合机器学习或深度学习的场景,但其实只是做一个数学运算的题目,比如这一题:
给定词典 [a, b, c, d, e],基于这个五单词词典的三个文档(document)内容如下:
DocA: [a, b, b, d, d] DocB: [b, b, b, e, e, e, d] DocC: [d, d, b, b, e] 如果使用 bag-of-words model 将每个文档表示成五维的向量,例如,DocA 可以被表示为 {a:1, b:2, c:0, d:2, e:0}。基于这三个五维向量,计算两两之间的余弦相似性(Cosine similarity),最相似的两个向量是?
这个题目,对很多没有太多自然语言处理(NLP)经验的同学来说,最难的主要是理解题目中 bag-of-words model、Cosine similarity 之类的基本概念。但因为是开卷,学习能力强的同学应该能快速查到这些概念的基本定义,然后根据 Cosine similarity 的公式,写几行代码,算出结果。善于偷懒的同学,其实也不难查到,像 sklearn.metrics.pairwise 包中的 cosine_similarity 函数,其实都是可以直接拿过来用的。
到底是什么题让电脑崩溃?
一般开卷在线笔试,是很难设计那种根据代码写出运行结果的题目的,因为参加考试的同学只要在电脑上运行一遍程序,就知道结果了。
我们命题组偏偏不信邪,设计出了几道编程和数学结合的题目,不仅给出代码,还无法通过直接执行得到答案。
比如说,其中一道题是这样的:
假设可以不考虑计算机运行资源(如内存)的限制,以下 python3 代码的预期运行结果是:
import math def sieve(size): sieve = [True] * size sieve[0] = False sieve[1] = False for i in range(2, int(math.sqrt(size)) + 1): k = i * 2 while k < size: sieve[k] = False k += i return sum(1 for x in sieve if x) print(sieve(10000000000)) 在正常配置的计算机里,这个题目里的代码是很难跑出结果的。这也是为什么题目描述里会强调"假设可以不考虑计算机运行资源(如内存)的限制"的原因。不相信这一点的同学当然会去尝试运行这段代码,但结果么,多半是内存异常,或者持续运行无响应。最糟糕的,电脑甚至会直接崩溃。实际考试时,同学报告了好几个崩溃案例;我猜,主要是在 Windows 系统中吧(笑脸)。
所以,遇到这种题是不能硬来的。做题的学生还是要回过头来,读代码,理解代码的含义。
这个代码的函数名sieve其实暗示了代码的功用,Sieve of Eratosthenes,这是用筛法计算质数个数的一个经典方法。当然,不知道筛法这个词也不重要,重要的是要从代码逻辑里,读懂最关键的几行其实是在把所有非质数都筛掉。就算读起来费劲,那么,至少能想到,把最后一行改成比较小的输入数字,比如 10,比如 100,比如 1000,运行一下试试吧。
这段代码的功能很明显:求 10,000,000,000 以内质数的个数。至于 10,000,000,000 以内质数的个数到底有多少,这个容易,搜索一下不就知道了?当然了,数学不好,或者不善于信息检索的同学,这个搜索估计也要费不少时间。
这种根据代码写运行结果,又可以开卷考试的命题思路,其实还有不少。比如实际考题里的另一个例子,是在用类似蒙特卡洛方法的思路,让计算机不断生成随机数,然后去暴力统计随机坐标落在平面上不同图形区域的计数比例,以逼近图形区域的面积或面积占比。真题如下:
下面的 python3 函数,如果输入的参数 n 非常大,函数的返回值会趋近于以下哪一个值(选项中的值用 Python 表达式来表示)?
import random def foo(n): random.seed() c1 = 0 c2 = 0 for i in range(n): x = random.random() y = random.random() r1 = x * x + y * y r2 = (1 - x) * (1 - x) + (1 - y) * (1 - y) if r1 <= 1 and r2 <= 1: c1 += 1 else: c2 += 1 return c1 / c2 (A) 4 / 3
(B) (math.pi - 2) / (4 - math.pi)
(C) math.e ** (6 / 21)
(D) math.tan(53 / 180 * math.pi)
这个题目,要计算面积比值的图形区域极其简单,只要搞懂了代码的基本思路,就不难把这个问题转化成一个毫无压力的初中几何题了。
算法题都不算难
这套卷子中,算法题的难度不大,但形式上会追求新颖,以便考察学生应对新问题的能力。比如下面这样的题目:
有一个画图用的函数库,提供三个 API 接口:
set_color(color) # 设置画笔颜色。初始画笔颜色为黑色。 move_to(x, y) # 移动画笔到给定的坐标。初始坐标为(0,0)。 line_to(x, y) # 在画笔的当前位置到给定的终点坐标之间画一条线段。 已知每调用 set_color 函数一次,要支付 3 元;每调用 move_to 函数一次,要支付 2 元;调用 line_to 函数免费。请问,要从初始状态开始,用这个函数库画出下图,最少支付多少钱就可以完成?(图中,左侧红绿蓝三条线段相互连接,右侧红绿蓝三条线段相互分离)
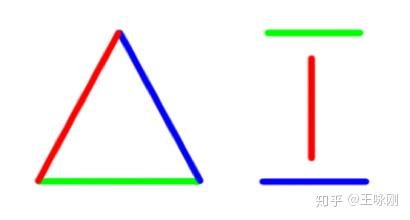
这个问题当然可以抽象成一个变形的最短路径问题,但显然没有那么复杂。思路缜密、清晰的同学在头脑中设计一条最佳路径,其实也不算困难。如果只在脑子里,或者只用纸笔想不清楚,那么,选择直接编程解决的方案也很容易。因为搜索空间不大,编程可以轻易穷举六条线段全排列的所有可能性,从里面找到最小的 cost 即可。
有趣的图灵奖得主问题
实际笔试中,一道大题是这么设计的(篇幅原因,下面题目中的字符串不完整,不能用于实际解题,只是一个示意):
有一张图灵奖得主的肖像照片,被一个学生用简单的异或加密方法,编码成了如下这样的字符串:
MG4rZiJpImkvaixpLGwrbjRxN3MxdzN3M3s……(篇幅原因,此处省略若干字符) 已知肖像照片是 64x64 像素的 0~255 级灰度图片,内存中用 raw bitmap 方式,每个像素用一个字节存储。对肖像照片的原始数据,学生使用的加密代码片段如下(Python3 代码,代码中的 key 值是未知的加密密钥):
_KEY_LEN = 2 bitmap = PIL.Image.open(image_path).tobytes() encrypted = [] for index, byte in enumerate(bitmap): encrypted.append(byte ^ key[index % _KEY_LEN]) return base64.standard_b64encode(bytes(encrypted)) 请问:这张被加密的照片,是以下哪位图灵奖得主的肖像?
(A) Marvin Minsky
(B) John L. Hennessy
(C) Donald E. Knuth
(D) Raj Reddy
(E) John McCarthy
(F) Edsger W. Dijkstra
(G) John Hopcroft
(H) Alan Kay
这题目很有趣,但不难。需要的只是学生比较灵活的头脑,和比较多的动手经验。机灵的人可能只写几行代码,就可以猜到结果。
首先,异或加密是一种幼儿园级别的加密形式,即便不知道秘钥,也不存在太多破解难度。学过密码学的同学,肯定特别清楚这一点。但没学过密码学的同学,在这里也没有太多劣势。只要不是被问题本身吓到,只要敢于或勤于动手做实验,总能很容易找到线索。
这题目完全不需要对异或加密的规律有任何深刻的认识。2 个字节长的秘钥,一共有 65536 种组合。其实,根本不需要尝试那么多。只要先猜着用一两千种候选秘钥来解码图片,同学们就不难发现,很多解码后的图像已经处于"半可读"状态了。
"半可读"的图像可以送进 Google 图片搜索或类似工具里找答案,也可以和选项列出的八位图灵奖得主的维基百科照片进行人工比对。
也就是说,题目本身并没有真正要求去破解秘钥,而是着重考察学生在遇到这样的全新问题时的逻辑思维能力,灵活利用手头各种工具的能力,以及勇于尝试的能力。
假如真的要破解秘钥(对异或加密来说,更准确的说法是,找到包含原始秘钥在内的一组近似秘钥),恢复出原始图片,其实也不是很难。一种可行的思路是写一个基于信号特征的分类器,将那些经过异或操作扰动的噪音图像和原始图像区分开。因为秘钥长度是 2 字节,用错秘钥时,解码后的图像里大多都有明显的纵向条纹,这显然是分类器可以借用的一个强特征。
从出题角度看,这个题的另一种变化形式是抛弃幼儿园级别的异或加密,而改用专业的对称加密算法来加密原始图像。当然,这时是需要限定候选秘钥的数量级的。这个情况下,错误的候选秘钥得到的输出,生成"半可读"图像的几率就大大减小了。当我们只能用暴力穷举的方法来找到包含清晰人脸的图像时,有的同学就会想到一个更有趣的解法:找一个人脸识别的API来,利用人脸识别功能,看哪个候选秘钥解码出来的图像里包含一张可识别的人脸。
莫尔斯电码问题
莫尔斯电码(Morse Code)因为是个经典的算法问题,本来不想过多介绍,但不断有同学问到,就多说几句吧。原题是这样的:
一个粗心的发报员在发送莫尔斯电码(Morse Code)的时候,忘记在发送字母和单词之间停顿,结果收报系统收到的是下面这样的一个没有分隔符的点(.)划(-)的序列(请忽略换行符)。
.-.-....-.-...--.-...-....--...-.-...-.--.------..-...-..-.-.---...-..-..---..-.. ....--..-.--.-...-.--......-.........-..-.----.-.....-....--.-.-.--.-..---..-.... ..-...-..-.--.-.----......-.--.-----..-------.-.-..---.-.-.--..-.-............... --...--....--..-....-.-----.....-...-------.-......-.........-..-..--.-....-...-- ....-.--.-.....--..-.....--..-.---.--...-.-.-..-.-.....---.-.-.-.----....-..-.... .--..----......-...-.--.-...--.....--.....-.......-....---..-..--...-------.--... .---..---.....-.-.-....-.-...--..-....---..--.--...-.-.-..-.-.....---.-.-.-.----. ...-..-.....--..----. 已知这份报文的原始内容是一部著名英文小说的片段,请问,这部小说的作者是:
(A) H. G. Wells
(B) J. K. Rowling
(C) Isaac Asimov
(D) Lewis Carroll
(E) Jack London
(F) Stephen King
(G) J. R. R. Tolkien
(H) Edgar Rice Burroughs
Google 搜索 "morse code without spaces",有非常多不同方式的讲解,比如比较经典的,用动态规划思路的解法。而且,网上还可以找到实际可以用来解码的源代码。考试时如果会搜索,几乎是不用自己编程序的。
当然,如果不想这么麻烦的话,还可以试着用手工穷举方式,解码前面 4~5 个英文字符,这个复杂度是可以接受的,因为原文的第一个字母是 "A",所以,前面 4~5 个字符最早出现的一组候选项里,很快就可以见到 "Alice" 这样醒目的单词——然后,如果同学们有好的阅读习惯,直接就可以猜到那本小说是——《爱丽丝漫游奇境》。
小结
DeeCamp 的笔试题其实都不太难。设计这些题目时,有趣、有区分度、覆盖的知识面广、能考察学生的灵活度和解决新问题的能力,这些都是我们最重要的考虑因素。
所有题目中,最有趣、笔试后被议论最多的,可能是这个有关二维码的问题:
下面这个被污损的二维码中,存储的信息是:

这个题目,其实主要是看学生在新问题面前,有没有一个比较符合逻辑的思考过程:
• 为什么二维码在污损之后,很多时候还是能被识别出来?
• 题目里给出的二维码,为什么微信的扫码器识别不出来?
既然是开卷,学生完全可以去搜索二维码的冗余设计。然后,学生基本会知道,其实二维码中间的小黑点部分,拥有大量的冗余,一般程度的变形和污损是不影响识别的,最影响识别的是三个大方框,因为它们起定位作用。了解了这样的知识,学生只要打开画板,把缺失最厉害的那个大方框补齐整,就可以微信扫码看结果了。
正如 DeeCamp 训练营本身一贯强调有趣、有用、贴近实战一样,DeeCamp 的在线笔试题在命题时,追求的也是这样一种思路(当然,命题组水平有限,差错或考虑不周的地方在所难免,还请大家多提批评意见)。
祝 DeeCamp 学员开心、进步!
来源:知乎 www.zhihu.com
作者:王咏刚
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载
没有评论:
发表评论