最近看到行为预测和规划的一些文章,想在这里介绍一下。先完成一半,做个上部吧。
"An Auto-tuning Framework for Autonomous Vehicles"
百度Apollo2018年的工作报告。
许多自动驾驶运动规划器通过优化奖励/成本功能来生成轨迹。不同驾驶条件下为4级自动驾驶车辆设计和调整高性能奖励/成本功能的工作是具有挑战性的。传统上,奖励/成本功能调整涉及大量的人力和在模拟和道路测试上花费的时间。随着场景变得更加复杂,调整改善运动规划器性能会变得越来越困难。
为了系统地解决这个问题,百度开发一个基于Apollo自动驾驶框架的数据驱动自动调整框架。该框架包括基于排名的条件逆强化学习(rank-based conditional inverse reinforcement learning,RC-IRL)算法、离线训练策略以及收集标记数据的自动方法。
这种自动调整框架适合于自动驾驶运动规划器调整。与大多数IRL算法相比,其训练是有效的,能够适应不同的场景。离线训练策略提供了一种在公共道路测试之前调整参数的安全方法。收集并自动标记专家驾驶数据和有关周围环境的信息,可大大减少手动操作。最后,通过模拟和公共道路测试可以检查该框架调整的运动规划器。
如图所示,为了扩大运动规划器场景覆盖范围并改善案例性能,建立这个自动调整系统,其中包括在线轨迹优化和离线参数调整两部分。在线模块专注于在约束条件下给出奖励功能,从而产生最佳轨迹。运动规划器模块与特定方法无关,可以使用不同的运动规划器,例如基于采样的优化、动态编程或强化学习,来生成轨迹。这些运动规划器的性能在量化最优性和鲁棒性等指标进行评估。通常在线部分的最优性可以通过最佳轨迹和生成轨迹的奖励函数值的差异来测量,鲁棒性可以通过给定特定情景下生成轨迹行为的方差来测量。 模拟和道路测试提供了对运动规划器性能的最终评估。
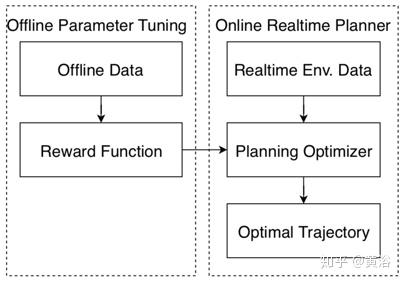
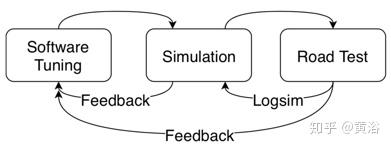
离线调整模块专注于提供可适应不同驾驶场景的奖励/成本功能。 运动规划奖励/成本功能包含描述平滑性和与周围环境交互的特征。 通常可以通过模拟和道路测试来调整奖励/成本功能。如下图所示,测试一组参数需要模拟和路上测试。然而,反馈循环是最耗时的组件,因为在仅从一组参数得出结论之前,需要数千或更多的驾驶场景验证。
RC-IRL方法学习奖励功能的想法包括两个关键部分:条件性比较(conditional comparison)和基于排名的学习(rank-based learning)。要注意到几点:1)其方法不是比较专家论证和最优策略的价值函数(value functions)期望,而是比较价值函数的状态;2)为了加快训练过程并扩大极端案例的覆盖范围,它对随机策略采样并与专家论证比较,而不是如策略梯度法那样先生成最优策略;3)背景差异(驾驶场景造成的)可能会显著影响调整后的奖励功能。
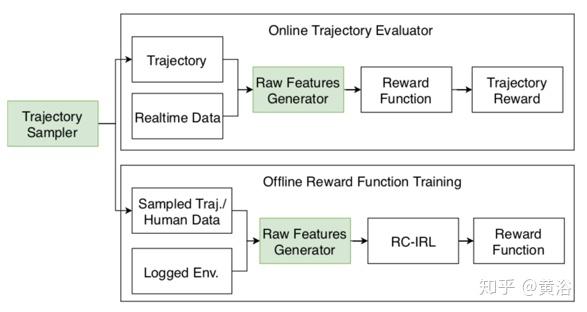
如图所示,Apollo自动驾驶系统的自动调整框架包括在线轨迹评估和离线参数调整两部分。为保持一致性,两个部分共享一些通用性模块。原始特征生成器从环境中获取输入并且无差别地评估采样或人类司机的驾驶轨迹; 轨迹采样器使用相同的策略分别为离线和在线模块生成候选轨迹。在线评估器从轨迹中提取原始特征之后,应用奖励/成本函数来提供分数。对所有得分轨迹排序或动态规划(例如基于搜索的算法)选择最终输出轨迹。
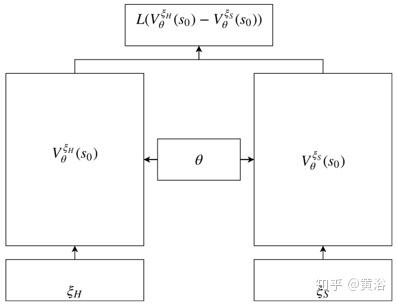
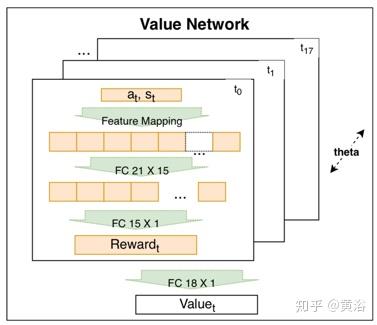
RC-IRL训练和一般Siamese网络一样,下图是RC-IRL中的Siamese网络。人类司机和采样轨迹的价值网络共享相同的网络参数设置。损失函数通过价值网络输出评估采样数据和生成轨迹之间的差异。
Siamese模型中的价值网络捕捉基于编码特征的驾驶行为。该网络是不同时间编码奖励的可训练线性组合。编码奖励的权重是可学习的时间衰减因子。编码奖励包括21个原始特征的输入层和15个节点的隐藏层。
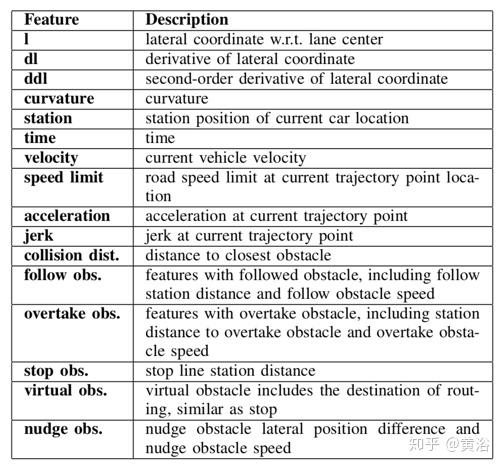
下表是采用的轨迹上点特征:
在测试中,给定站点-横向坐标系(station-lateral coordinate system)的路径轮廓(path profile),如果与自车的移动路径存在任何交互,则障碍物和预测移动轨迹投影在站点-时间图(station- time graph)上。目标是在站点-时间图上生成速度曲线,安全地避开障碍物并保持平稳驾驶。通过优化成本/回报(cost/reward)功能来生成满足轨迹平滑度、不同障碍物距离和路径平滑度等方面的最佳速度曲线。
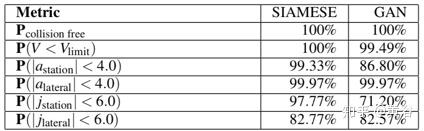
下表列出了与运动规划相关的关键绩效指标。 在表格中,将Pcollision free列为运动规划的安全指数,并将范围内横向和纵向加速度的概率以及范围内的抖动约束列为轨迹平滑度的指标。在模拟中,RC-IRL的SIAMESE网络比GAN训练的奖励功能表现更好。
"Adaptive Behavior Generation for Autonomous Driving using Deep Reinforcement Learning with Compact Semantic States"
在交通规划中做出正确的决策是一项具有挑战性的任务,很难仅根据专业知识进行建模。这项工作用深度强化学习(Deep RL)基于紧凑的语义状态表示来学习机动决策。这个实现了一个跨场景的环境模型以及行为的自适应,即无需重新训练,它即可实现所需行为的在线更改。
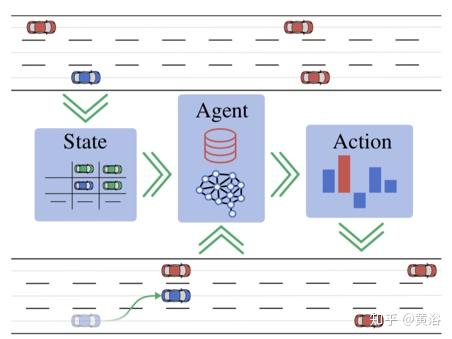
类似于雷达或激光雷达传感器,其神经网络的输入是模拟的目标列表,同时叠加一个相关的语义场景描述。状态(state)以及奖励(reward)分别通过行为自适应和参数化来扩展。可以看出,只有很少的专业知识和一系列中级行动(action),这个代理(agent)仍然能够遵守交通规则并学会在各种情况下安全驾驶。
下图是DRL的示意图:初始交通场景被转换为紧凑的语义状态表示s,作RL代理的输入。代理估计具有最高回报(Q值)的动作a并执行它,例如改变车道。之后,收集奖励r并达到新的状态s'。 状态转换(s,a,r,s')存储在代理的重放(replay)存储器中。
定义以自我车辆vego∈V为中心的关系网格。行对应于关系车道拓扑,而列对应于车道上的车辆拓扑。下图展示如何构建关系网格:
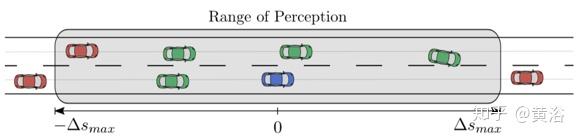
(a)自我车辆(蓝色)在双车道道路上行驶。其他五个车辆在其传感器范围内。基于车辆范围Λlateral=Λahead=Λbehind= 1,在语义状态表示中仅考虑四个车辆(绿色)。
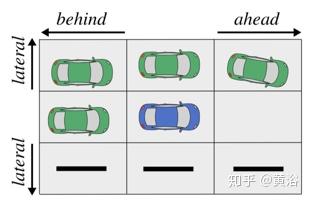
(b)由(a)的场景产生的关系网格,其中Λlateral=Λahead=Λbehind= 1。此外,右边没有相邻的车道,也在网格中表示出来。
在上图中,用Λlateral=Λahead=Λbehind= 1的车辆范围Λ,将示例场景(a)变换为关系网格(b)。处于传感器范围内的红色车辆未在网格中表示。由于在自我车辆同一车道的前方没有车辆行驶,因此网格中相应关系位置是空的。
接着上图,下图介绍如何构建可视化的场景实体关系(entity-relationship)模型:车辆拓扑结构由车-车关系建模,而车道拓扑结构由车道-车道关系建模。
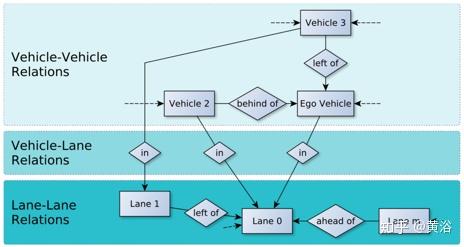
但是该表示是大小可变的,还包括除了给定驾驶任务相关方面以外的其他方面。为了作神经网络的输入,将其转换为仅包含最相关的、大小固定的关系网格。
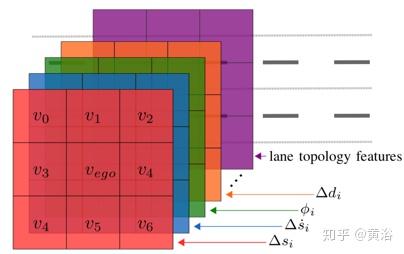
如图所示,在关系网格每个特征包含一层。车辆特征fvi和fvego共享层,分别位于vi和vego单元格中。 车道特征fkl位于网格第k行的附加层。
虽然也能够处理自动驾驶汽车中预处理数据,但仍然使用交通仿真工具SUMO测试。下图所示,在SUMO检索出当前状态,并转换为语义状态表示。 这是RL代理的输入,用TensorForce库进行训练。选择的动作被映射到模拟的相应状态变化。基于初始状态、所选动作和后继状态,计算代理的奖励。
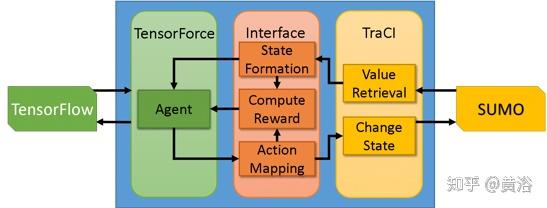
为了监督代理去遵守流量规则,在两种不同的流量方案中训练和评估,如下图所示: (a)代理有义务在最右边的车道行驶,除了其他限制之外,不得从右边通过其他车; (b)允许代理在进入匝道时加速,还可超过其左侧的车辆。但必须在结束前离开入口。
下图是超车动作示意图。 代理车(蓝色)在较慢的车辆(绿色)之后。 在这种情况下,左侧的行动"换道"具有最高的估计Q值。 换道后,代理加速并超过较慢的车辆。 随后,代理变回最右边的车道。

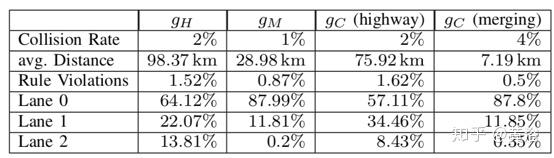
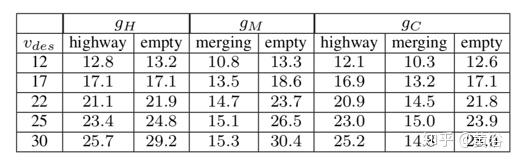
下表是训练的代理结果。 代理gH(高速公路)和gM(合并坡道)仅在各自的情景下评估,同时评估gC(高速公路和合并坡道)。 每种方案都单独列出gC结果。
下表是给定不同的所需速度[m / s]下代理的平均速度。已经在正常交通密度的训练场景和空旷的高速公路做评估。虽然代理不是都能够精确地达到所需的速度,但其行为适应不同的参数值。
"Probabilistic Prediction of Interactive Driving Behavior via Hierarchical Inverse Reinforcement Learning"
为了安全有效地与其他道路参与者进行交互,自动驾驶车必须准确地预测周围车辆的行为并相应地进行规划。这种预测是概率性的,以解决人行为的不确定性。这种预测也是交互式的,因为预测车辆的轨迹分布不仅取决于历史信息,还取决于与其交互的其他车的未来规划。
为了实现这种交互觉察的预测,提出了一种基于分级的逆强化学习(IRL)的概率预测方法。1)明确地考虑了涉及离散和连续驾驶决策的人类司机分级轨迹生成过程,基于此预测车辆所有轨迹的分布定义为离散决策划分的混合分布;2)分级地应用IRL学习人类真实驾驶的分布。
该方法侧重于预测两个车辆司机的交互行为:主车辆(H)和预测车辆(M)。其他所有现场车辆被视为周围车辆(O)。用ξ来表示历史车辆轨迹,ξˆ表示未来轨迹。
很明显,预测车辆所有可能轨迹的概率分布取决于自身的历史轨迹和周围车辆的轨迹。在数学上,这种时域状态依赖关系可以建模为条件概率密度函数(PDF):
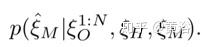
预测车辆所有可能轨迹的概率分布也应该以主车辆的潜规划为条件。这样上面的条件PDF可以改写成
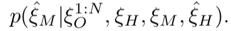
人类司机的轨迹生成过程是概率性的和分级的。它涉及离散和连续的驾驶决策。离散驾驶决策将未来轨迹的"粗略"模式,或同伦类(homotopy class),确定为游戏理论结果(例如,让步或通过),而连续驾驶决策影响轨迹的细节,例如速度、加速度和平滑度。
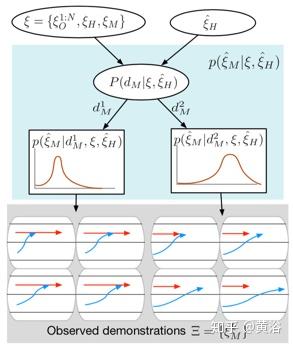
下图展示在驾驶换道场景的概率的和分级的轨迹生成过程。其中预测的车辆(蓝色)试图合并到主车辆占用的车道(红色)。给定所有观测到的历史轨迹ξ={ξ1:NO, ξH , ξM }以及对主车辆未来轨迹ξH的置信,预测车辆在所有轨迹空间上的轨迹分布先被离散决策划分成:后合并(d1M)和前合并(d2M)。在不同的离散决策下,连续轨迹的分布看着不同,其中每一个表示为概率分布模型。观察到的操作就是满足这个分布的样本。
条件分布被定义成混合分布,明确地捕获人类司机离散和连续驾驶决策的影响:
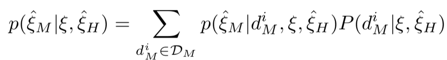
然后,提出分层的应用逆强化学习(IRL)来学习观察到的人类司机操作的所有模型。基于最大熵的原理,假设所有司机更有可能做出降低成本的决策(离散和连续),这引入了一组取决于成本函数的指数分布,而兴趣在于找到最终带来轨迹分布与给定司机操作集Ξ中观察到的轨迹相匹配的最佳分层成本函数。
由于轨迹空间是连续的并且实际的操作相对噪声是局部最优的,因此采用局部最优示例的连续逆最优控制(Continuous Inverse Optimal Control)方法。
对连续驾驶决策而言,在离散的决策下,假设每个轨迹的成本可以由一组选定的特征线性地参数化,那么给定的实际操作数据,其连续空间IRL的目标是找到实现以下优化函数的最佳参数向量
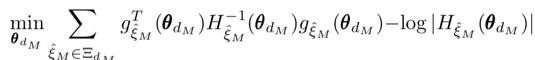
对离散驾驶决策而言,假设成本较低的决策是指数可能,那么离散空间IRL的目标是找到实现以下优化函数的最佳参数向量
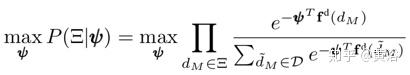
取对数分布和梯度下降迭代,其参数计算公式是
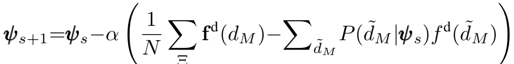
其中
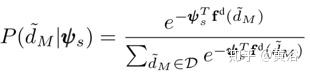
本文实验是从Next Generation SIMulation(NGSIM)数据集中收集人类驾驶数据。安装在周围建筑物顶部的摄像机捕捉高速公路的驾驶行为/轨迹,其中轨迹的采样时间为△t = 0.01s。在加州80号州际公路选择134个车辆闸道合并轨迹,并将它们分成两组: 80为训练集以及其他54为测试集。
下图显示道路图(road map)和一组示例轨迹。现场有四辆车,一辆要合并的车辆(红色),一辆保持车道的车辆(蓝色),还有两辆周围车辆(黑色),其中一辆在蓝色车前面,另一辆在后面。感兴趣的是分析合并车辆(红色)和车道保持车辆(蓝色)的交互式驾驶行为。

同样采用分层IRL方法来模拟合并车辆和车道保持车辆的条件概率分布。对车辆从闸道合并情景,其驾驶决策如表所示。

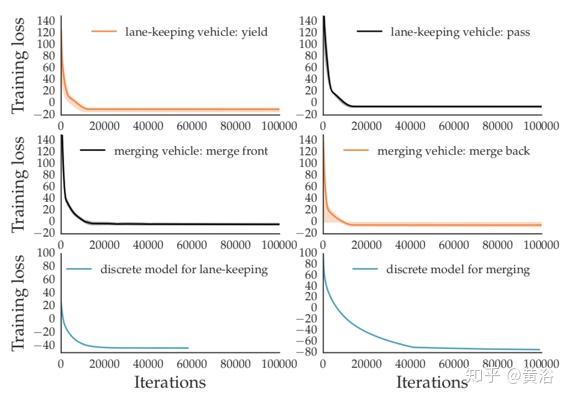
实验中使用Tensorflow实现分层IRL算法。下图给出了有关连续和离散驾驶决策的训练曲线。由于层次结构,在不同的离散决策下学习合并车辆和车道保持车辆的有四个连续分布模型。从训练集中随机抽取轨迹子集并执行多个训练。如图所示,每个连续模型的参数小方差地一致收敛。
在测试中,通过学习的连续成本函数求解有限时域滚动(finite horizon)模型预测控制(MPC)问题,从而在不同的离散驾驶决策下生成最可能的轨迹。
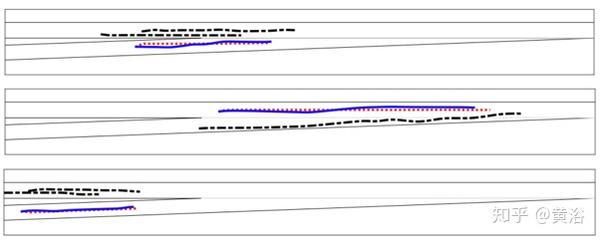
下图是三个说明性示例:红色虚线和蓝色实线分别表示预测的最可能轨迹和真实轨迹;粗黑点划线是其他车辆的轨迹;可以看出预测轨迹非常接近真实轨迹。
"Risk-averse Behavior Planning for Autonomous Driving under Uncertainty"
自动车辆必须能在周围环境中导航,可以部分地观察同一道路的其他车辆。自主车辆测量中的不确定性(uncertainty)来源包括传感器融合误差、天气或目标检测延迟导致传感器的有限范围、遮挡以及诸如其他司机意图的隐参数。
行为规划必须考虑确定未来车辆机动的所有不确定因素。本文结合QMDP,无迹变换(unscented transform)和蒙特卡罗树搜索(MCTS),提出了一种不确定下可扩展的规避风险(risk-averse)行为规划框架。
考虑模块化堆栈,基于传感器输入和地图信息推断道路世界模型(road world model, RWM)。设st表示自车的状态和时间t与自车同一道路的其他目标,其中第j个目标状态定义为
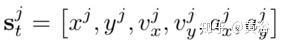
它们分别代表物体的横向和纵向位置、速度和加速度;为了简单起见,扔掉时间指标。
考虑一个分层行为规划器,其中动作空间A定义为高级动作集合AHL = {LaneKeep,LaneChangeR,LaneChangeL,Yield,Negotiatelanechange}的组合,还有一组参数Θ指定如何执行动作(安全时间间隔、前方车辆的最小距离、所需速度、最大加速度/减速度、礼貌水平、以及变道的方向和最大时间/距离)。
将行为规划器动作传递到运动计划和控制模块,可生成轨迹规划和油门/转向控制。根据RWM的时间序列输入,行为规划器根据风险规避度(risk-averse metric)选择一个操作:
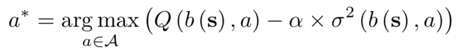
这是一个部分可观察马尔可夫决策过程(POMDP)问题,其精确的解决方案在计算上是难以实现的。相反,用无迹变换(UT)的QMDP框架来生成置信分布的采样点。
要计算给定状态s的QMDP(s,a),这里使用一个在线计划器,尤其是采用一个蒙特卡罗树搜索(MCTS)。
模拟实验中,主要研究不确定性的两种驾驶情景:1)道路上超出传感器范围的静止物体,以及2)有限视野的高速闸道,如图所示。
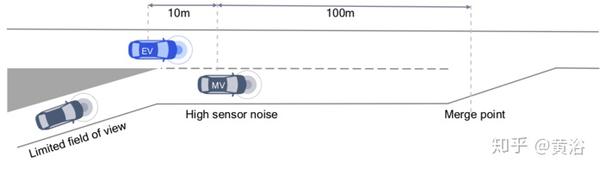
考虑两种基于MCTS的方案:1)无噪声观测值的MCTS-Genie,2)基于噪声测量做出决策的MCTS-Noisy。自车和合并车的初始速度均为20m / s。如图比较了候选算法的自车速度,如表提供了车辆在合并点更多的状态信息,这样实现一个合并车速度的初始测量低于实际值的噪声。
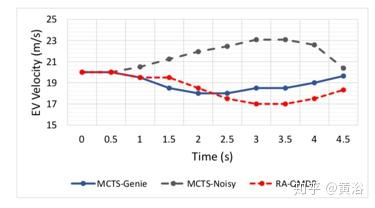
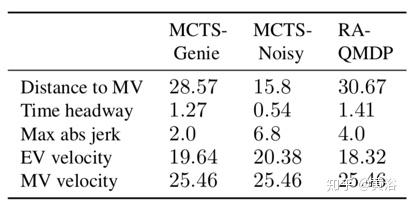
- MCTS-Noisy开始时假设合并车比自车慢,并且决定自车加速在到合并点之前越过合并车。然而,几秒钟后,它意识到初始值差太远,实际上它无法越过合并车。虽然它采用了强减速(加速度为-6.8m / s3),但在合并点之前没有足够的时间来创建安全间隙(参见表)。
- MCTS-Genie观察合并车的实际速度,从一开始就做出正确的决定。
- RA-QMDP(选择α= 0.01和ε= 1)采用三个采样点,其中一个认为合并车的速度比RWM报告的速度快。然后,它做出一个规避风险的决定,迫使自车放慢速度并增加与合并车的差距。请注意,RA-QMDP在做出决定时有一些延迟,因为它的评估也受到另外两个采样点的影响,这两个采样点表明合并车在减速并且可能有机会越过它。
"Zero-shot Deep Reinforcement Learning Driving Policy Transfer for Autonomous Vehicles based on Robust Control"
虽然深度强化学习(深度RL)方法具有很多优势,应用于自动驾驶,真正深度RL应用已经因源(训练)域和目标(部署)域之间的建模差距而减慢。与当前的策略迁移方法(通常限制用不可解释的神经网络表示作为迁移特征)不同,本文建议在自动驾驶中迁移具体的运动学量。
提出的基于鲁棒控制的(robust-control,RC)通用迁移架构,称为RL-RC,包括可迁移的分层RL轨迹规划器和基于扰动观测器(disturbance observer,DOB)的鲁棒跟踪控制器。利用已知标称(nominal)动力学模型训练的深RL策略直接传递到目标域,应用基于DOB的鲁棒跟踪控制来解决建模间隙,包括车辆动力学误差和外力扰动(external disturbances),例如侧向力(side forces)。所提供的模拟验证实现了跨越多种驾驶场景的零击迁移(zero-shot transfer),例如车道保持,车道变换和避障。
所提出的RL-RC策略迁移体系结构由基于RL的深层高级规划模块和基于RC的低层跟踪控制器组成。总体方法包括离线深入的RL策略训练和在线策略迁移,如下图所示。在离线源域(source domain),预训练将感知输入映射到控制命令的深度RL策略,驱动源车(source vehicle)产生完成控制任务的轨迹。对于目标域(target domain)的在线迁移,它显示了系统如何迁移源车的驾驶策略。
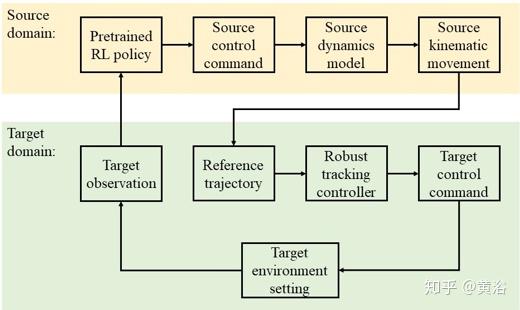
根据感知观测量,在与目标代理(target agent)相同的设置下系统构建虚拟源代理(source agent)。在虚拟源域,预训练策略控制虚拟源代理执行有限生命期(finite horizon)的驾驶任务,产生运动状态轨迹,用作目标车辆的参考。给定参考轨迹,目标代理使用闭环的鲁棒跟踪控制器生成目标车辆的实际控制命令。
当目标环境继续发展时,收集新时刻的观测量,系统重复相同的过程。在这种体系结构中,运动学特征无需更改就可以传递,建模间隔可以通过RC进行补偿。为了在虚拟源域生成参考轨迹,要训练一个深度RL策略网络,该网络将感知输入直接映射到运动状态轨迹。
RL-RC系统有两个主要基本假设:
(i)假想的源代理规划的轨迹可满足目标任务;
(ii)让目标车辆跟踪源车辆产生的轨迹是可行的。
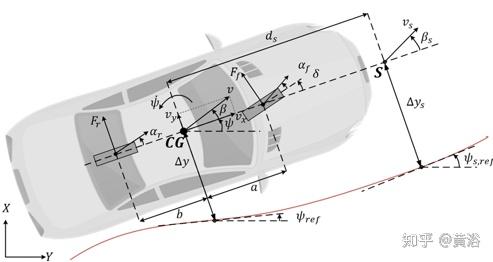
以上这些假设是合理的,因为源车辆和目标车辆及其设置是相似de,而RL-RC只对这种情况是有效的。下图是模拟环境和控制器中线性跟踪模型的术语说明。
要使用深度RL取学习驾驶策略,需将驾驶任务定义马尔可夫决策过程(MDP)。由于不同的任务具有不同的观测值,因此将观测值的群(clusters)定义为实体(entities)。
如表显示车道保持(LK)、车道变更(LC)和避障(OA)的任务界面。在实施中,应用模块化不同驾驶属性的分层RL模型。这些属性指的是驾驶行为,例如障碍物检测、车道选择和车道跟踪。

而这个表和下图给出RL详细的模块接口及其用法。使用分层RL模块为车道保持(LK),车道变更(LC)和避障(OA)任务提供组合策略。

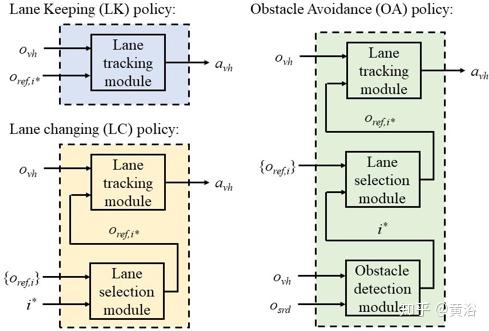
从理论上讲,可以使用任何一种方法(包括深度RL)来优化所有三个基本模块。在实施中,为简单起见,车道选择和障碍物检测均基于规则,并进行了合理的优化。使用无模型的深度RL优化了车道跟踪。与E2E训练相比,分层实现的好处是,与复杂的高级驾驶策略的E2E训练相比,基本的属性模块更易于优化。
要设计控制器,首先需要获得跟踪问题的近似线性模型。本文横向动力学采用恒速线性自行车模型
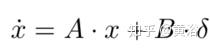
用以上公式,并应用前向欧拉离散方法(forward Euler discretization),可以得到整体跟踪模型,其框图如下:
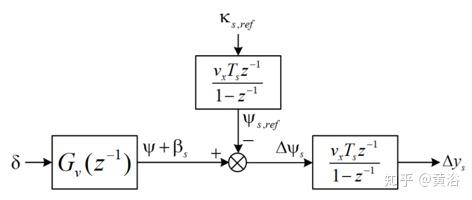
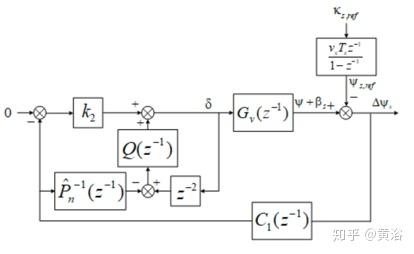
基于源车辆的标称模型设计鲁棒控制器。然后将扰动观测器(DOB,disturbance observer)添加到标称反馈控制器,整个闭环系统的框图如下所示:
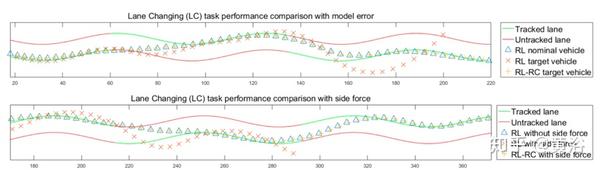
下图是在有建模间隔的换道(LC)任务中RL和RL-RC的驾驶行为比较。
"Multimodal Trajectory Predictions for Autonomous Driving using Deep Convolutional Networks"
交通行为存在高度不确定性,自驾车在道路上会遇到大量情况,创建一个完全广义化的系统非常困难。为了确保安全和运行有效,需要自动驾驶车辆来解决这种不确定性并预测其周围的交通参与者可能的多种行为。
一个解决方法是预测参与者可能的多个轨迹,同时估计出现的概率。该方法将每个参与者的周围上下文信息编码成一个光栅图像,作为深度卷积网络的输入,自动导出任务相关的特征。
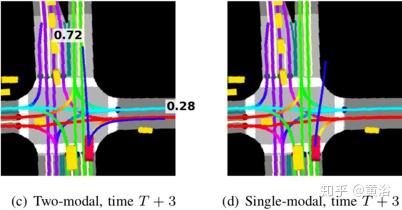
首先,光栅化那些参与者特定的BEV光栅图像,该图像对参与者周围以及其邻近参与者(例如其他车辆和行人)的地图进行编码。如下图为例,对未来6秒车辆轨迹的多模态建模; 预测的轨迹以蓝色标记,在轨迹的末尾指示其概率。
然后,给定第i个参与者的光栅图像和时间步长tj的状态估计sij,用CNN模型预测M个可能的未来状态序列以及每个序列的概率pim,使得åm(pim)= 1,其中 m表示模式索引。
简化推断第i个演员的未来x-和y-位置的任务,而其余状态可以通过sij和未来位置估计。时间tj的过去和将来位置以时间tj参与者状态导出的参与者-中心坐标系来表示,其中前向是x轴,左向是y轴,参与者的边框质心是原点。
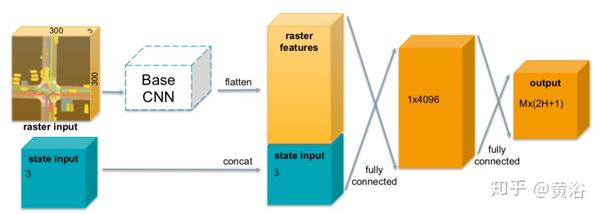
下图是采用的网络架构图,参与者特定的、分辨率为0.2m的300×300 RGB光栅图像和参与者当前状态(速度,加速度和航向变化率)作为输入,输出M个未来x-和y-位置的模式(每个模式有2H个输出) )及其概率(每个模式是一个标量)。 这样每个参与者的输出为(2H +1)M。 概率输出通过softmax层传递确保总和为1。任何CNN架构都可以用作基础网络,这里使用MobileNet-v2。
它提出一种多轨迹预测(Multiple-Trajectory Prediction,MTP)而不是单轨迹预测(STP)损失函数,该损失可以显式地对轨迹空间的多模态建模。首先,在时间tj处第i个参与者第m个模式的单模损失L定义为地面真实轨迹与第m个模式的预测轨迹之间的平均位移误差(L2-范数):
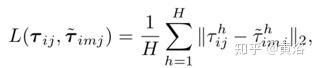
而MTP损失定义如下:
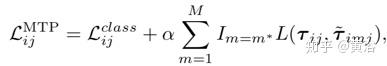
其中
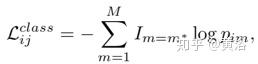
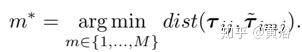
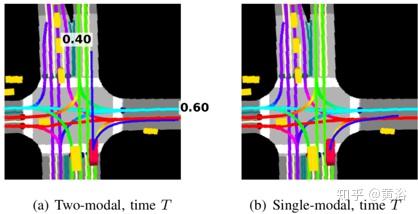
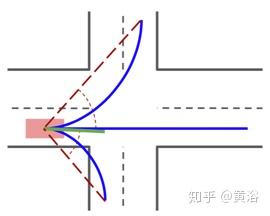
但是,损失中的距离函数不能很好地模拟交叉路口的多峰行为,如图所示。 为了解决这个问题提出了一种函数,该函数考虑从参与者位置看去、两个轨迹最后点之间的夹角来测量距离,从而改善了交叉路口场景的处理性能。
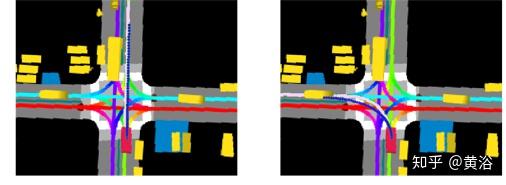
假设有可以遵循的可能车道知识,以及过滤不太可能车道的车道评分系统,那么添加另一个光栅化层,对该信息进行编码并训练网络输出车道跟随轨迹。 然后,对于一个场景,生成具有多个要跟随车道的栅格,从而有效地推断出多个轨迹。下图显示了同一场景的栅格,但是使用两条不同的跟随车道,这些车道用浅粉红色标记,一条直线行驶,一条向左转。 该方法输出的轨迹很好地遵循了预期的路径,并且可以生成寻车道车辆的多个轨迹。
下图展示的是,当增加模式数M时,在交叉路口场景参与者直行的的可视化输出。模式数M = 1(即单轨迹预测STP模型)时,推断的轨迹大致是直行和右转模式的平均值。M = 2时,可以在直行和右转模式之间清楚地分开。 此外, M = 3时也会出现左转模式,尽管可能性较低。M = 4时,会产生有趣的结果,直行模式分为"快速"和"慢速"模式,从而模拟了参与者纵向运动的可变性。
"Exploring the Limitations of Behavior Cloning for Autonomous Driving"
车辆驾驶需要对各种复杂的环境条件和代理行为做出反应。对每种可能的场景进行建模是不现实的。相比之下,模仿学习(imitation learning)在理论上可以利用大量的人类驾驶数据。特别是行为克隆(behavior cloning)已成功用于端到端学习简单的视觉运动策略(visuomotor policies),但扩展到全方位的驾驶行为仍然是一个未解决的问题。
本文提出了一个新的基准,实验性地研究行为克隆的可扩展性和局限性。结果说明,行为克隆最好,即使在看不见的环境中执行复杂的横向和纵向机动,这些都是不会明确被编程的。不过,众所周知的局限性(数据集偏差和过拟合的原因)、新的泛化问题(动态目标的存在,以及缺乏因果模型)以及训练不稳定性仍然需要进一步研究,这样行为克隆技术才能逐渐实现真实世界的驾驶。
行为克隆是一种监督学习形式,可以从离线收集的数据中学习传感动力策略(sensorimotor policies)。唯一的需求是专家动作-相关输入传感观测对。这里用自动驾驶汽车扩展形式,称为条件模拟学习(CIL)。它用高级导航命令c来消除模仿围绕多种交叉类型的歧议。
给定一个访问环境状态x的专家策略π*(x),执行此策略可生成数据集,D = {⟨oi,ci,ai⟩} Ni = 1,其中oi是传感器数据观察,ci是高级命令(例如,下一个右拐,左拐或停留在本车道上)和ai =π*(xi)是最后产生的车辆动作(低级控制)。观察oi = {i,vm}包含单个图像i和添加到系统的自车速vm适当地对道路上的动态目标作出反应。没有速度上下文的话,模型无法了解是否,或什么时候,应该加速或者刹车以达到所需的速度或者停止。
仅基于观察o和高级命令c来学习θ参数化的策略π并产生与π*类似的动作。最小化模仿成本l可获得最佳参数θ*:
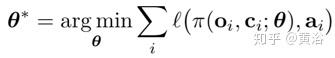
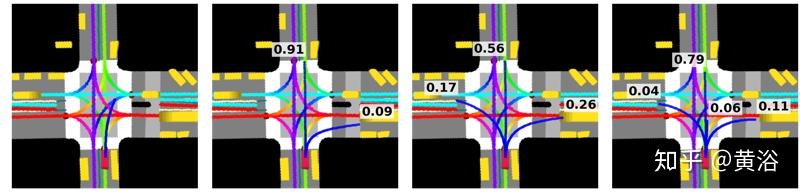
为了测试在线评估学习策略π(oi,ci; θ)的性能,计算给定基准上策略π性能的得分函数值。行为克隆的限制,除了分布漂移之外,还有其他3个:
- 自然驾驶数据集的偏差;
- 因果混乱;
- 差异很大。
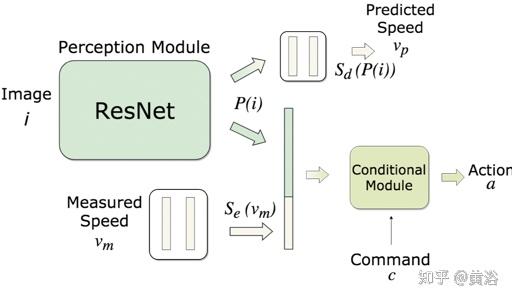
如图所示,所提议的网络架构,称为CILRS,用于基于条件模拟学习(CIL)的端到端城市驾驶。 其中ResNet感知模块处理输入图像,输出潜空间,接着是两个预测头:一个用于控制,一个用于速度。
开源的模拟仿真器CARLA提供多样化、逼真且动态的、具有挑战驾驶条件的环境。这里推出一种名为NoCrash的大型CARLA驾驶基准,旨在测试自车能处理复杂事件的能力,主要是由场景中变化的交通状况(例如交通信号灯)和动态代理所引起。
提供了三个不同的任务,每个任务对应25个目标导向的剧集(episode)。在每一集代理从一个随机位置开始,由高级规划器指导进入某个目标位置。三个任务如下:
- 空城:没有动态目标。
- 规则交通:中等数量的汽车和行人。
- 密集交通:大量的行人和繁忙的交通(密集的城市情景)。
与CARLA基准测试类似,NoCrash有六种不同的天气条件,其中四种在训练中,两种在测试中。还有两个城镇场景,一个用于训练,另一个用于测试。
下表是与原始CARLA基准测试的最好性能进行比较。 "CILRS"指使用速度预测分支的基于CIL的ResNet网络, "CILR"指没有这种速度预测基于CIL的ResNet网络。 该表报告了每种情况下成功完成剧集的百分比,每五次运行选择最佳。

下表是在NoCrash基准测试的结果。因为CARLA具有显着的非确定性,取三次运行的平均值和标准差。

剩余文章放在下部分。
来源:知乎 www.zhihu.com
作者:黄浴
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载
没有评论:
发表评论