

前几天,有幸参加了百事通组织的一场活动,有机会向一些行业大咖请教AI+法律的问题。
但在活动过程中,我发现当前法律行业对AI的认知仍然没有脱离2017年的论调,更多是从【机器认知】的角度来谈AI,认为AI会逐步具备对法律概念的认知能力,并在认知能力的基础上自行提供法律服务,从而取代传统的法律人工服务,进而颠覆整个行业,到达科幻电影中描述的【全智能法律系统】。
实际上从我们华宇元典这几年的实践来看,这一轮的AI革命从爆发之初就与大数据、机器学习不可分割。而大数据、机器学习更多是一种【通过数据驱动方式达到智能效果的路径】,而非真正地让机器具备像人类一样的认知能力。
举个简单例子,法律人工作中常用的法律检索,可以说是当前与AI技术融合度最高的领域。
传统的法律检索(以案例检索为例),首先是通过法律人对案件情况的梳理,从案情中【提炼】关键词,而后借助【关键词】查找目标案例。这种方式找到的目标案例中一定会【包含】我们设定的关键词。如果案例中不包含关键词,也就不会被系统推送给我们,实际上运用的是【关键词再现】的操作方式。
但这种检索方式往往有两个弊端:
第一个弊端是所谓的【关键词悖论】,这点在做陌生领域的法律研究类检索中尤为明显。我们做法律检索正是因为对这个领域不熟悉,但提炼关键词又要求我们了解这个领域,可以针对这个领域的理解提炼出合适的关键词。
因为不理解去检索,但做检索的前提是理解,这就是我们面临的关键词悖论。
第二个弊端在于传统关键词检索有时候很难检索到目标案例。比如我们设定"律师"作为关键词,想检索有律师参与辩护的刑事案件。但结果输入关键词,检索平台会把所有包含"律师"这个词汇的裁判文书全部给你推送过去,我们还需要通过人工的方式做二次筛选。
换句话说检索平台并不知道我们想要什么,它只是单纯地按照【关键词再现】原则做信息汇总。
通过AI方式我们就可以克服这两个弊端。
正如刚刚提到的,目前的法律AI是一种【通过数据驱动方式达到智能效果的路径】,这也是AI优化传统法律检索所遵循的路径。
比如对上述两个检索弊端的解决,AI化的处理方式就是【知识图谱+数据标签】。
先说说知识图谱。
举个简单例子,我们做法律检索的时候,以"盗窃"作为关键词,传统的法律检索方式会把包含"盗窃"这个词的案例全部推送过来。但实际上,盗窃还可以再细分,按量刑影响细分为"一般盗窃行为、入户盗窃、多次盗窃、盗窃油气或者正在使用的油气设备"。对这些细分的因素,不了解刑事法律的人往往很难掌握,就会遇到【关键词悖论】。这个时候需要系统给予【一定的提示】,比如元典智库这款检索平台中就用【要素】的方式做提示:
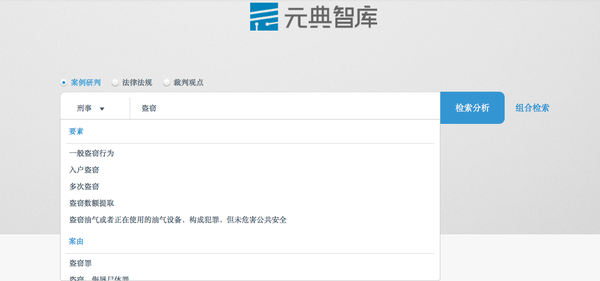
而这种要素提示所依托的就是【知识图谱】。
想要实现这种效果,系统必须提前建立关于盗窃的知识图谱,将与盗窃相关联的因素做聚合,形成可以应用的知识网络。
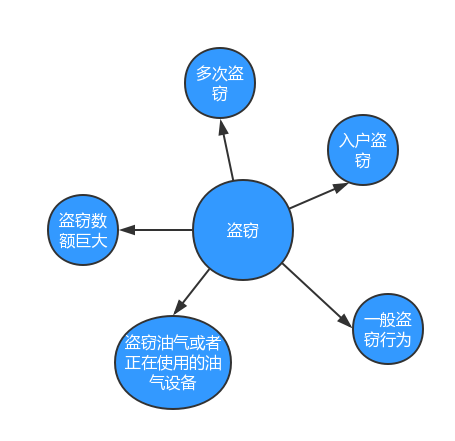
有了这个知识图谱做基础,我们做盗窃相关的案件检索,只需要输入盗窃这个关键词,并在系统的引导下,确定盗窃的具体情形,并在这个情形之下关联更精准的裁判案例,从而解决关键词悖论的问题。
但我们要注意,知识图谱的解决方式并不是说让系统知道盗窃这个概念,而是让系统在盗窃以及与盗窃相关的因素之间建立联系,从一个因素A可以联系到因素B、因素C,甚至因素B1、C1,有需要可以进一步往下延伸。
实际上这也是一种数据驱动达到智能效果的方式,系统不知道什么是盗窃,但通过知识图谱,我们可以教会系统达到对盗窃认知的效果。
第二个关键因素是数据标签,这种数据标签实际上是【用户偏好标签】。
比如你是一个刑辩律师,你在检索系统中设定了【刑辩律师】这个用户偏好标签。这其实是告诉系统,我一般情况下需要了解的是刑事类案件而非民事类案件,系统了解这个标签后,在检索中给你优先收集并排在检索前端的就是刑事类案例。这就如同今日头条,前期一定是通过用户偏好标签对用户形成认知,而后期会通过【用户操作行为】加深对用户的认知。
这种方式的实质也是数据驱动,是通过用户和系统之间的【互动】,形成对用户数据的积累,进而通过数据+算法【预测用户偏好】,达到的效果是【让系统认知用户】,并给用户推送符合用户偏好的裁判案件或者信息。
但需要注意这里的认知仅仅是一种数据处理方式,而不是说像人一样真的认识你、了解你,只是说系统可以通过数据+算法的方式做出【更精准、更个性化】的信息收集。
这就解决了传统法律检索的第二个弊端,系统可以在一定程度上知道你想要什么。
从上述法律检索的案例,我们不难看出,这一阶段的AI实际上还只是具备通过数据驱动解决问题的能力,但所谓的【机器认知】还为时尚早。而这种方式下,AI必然会面临两个方面的困境:
1.AI只能完成某一类或者某几类任务,而无法实现通用效果,成为多面手。扫地机器人只会扫地,肯定不会叠被子;阿尔法狗蛋下围棋是天才,但下象棋未必能赢得过刚入门的新手。同样的道理,前段时间爆红网络的LawGeex可以在合同审查上完胜律师,但如果比赛的内容发生变化,让LawGeex和律师比赛法律咨询,结果可以想象,LawGeex就不是人工智能而是机器白痴了。
2.数据成为AI发展的基础。想要实现数据驱动解决问题,前提必须有海量的数据做基础。这也是为什么这一代AI会从google、Amazon、BAT等大公司兴起,原因即在于这类公司掌握了大量的数据,可以通过【简单粗暴】的方式借助数据达到智能效果。正如吴军老师在其著作《智能时代》中提到的"google的自动驾驶驾驶汽车实际上是google街景项目的延伸,是对街景项目积淀数据的再利用"。
具体到法律领域也是如此,法律AI所依托的也是数据驱动的方式,自然也需要大量数据积淀,在这个领域【谁掌握了数据,谁才能真正地胜出】。
至于法律人所担心的AI颠覆法律,说实话根本不存在什么颠覆,只是新方法与旧方法的冲突。
比如图片类内容的合规审查,采用机器识别的方式,结合具体的算法可以达到高效快速的合规审查;借助增加人员、扩大合规团队,采用人工的方式也可以完成一张一张图片的合规审查。
两种方式各有利弊,目前更多是两种方式的相互结合,所以这一阶段法律从业者真正需要思考的问题不是如何避免被AI所颠覆,而是应该想方设法和AI做融合,将AI作为一种完成工作的新的方法。
来源:知乎 www.zhihu.com
作者:元典法律智能
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载
没有评论:
发表评论