其实,不只是iPad,手机也可以。
痛点
我组织过几次线下编程工作坊,带着同学们用Python处理数据科学问题。
其中最让人头疼的,就是运行环境的安装。

实事求是地讲,参加工作坊之前,我已经做了认真准备。
例如集成环境,选用了对用户很友好的Anaconda。
代码在我的Macbook电脑上跑,没有问题。还拿到学生的Windows 7上跑,也没有问题。这才上传到了Github。
在发布的教程文章里,我也已经把安装软件包的说明写得非常详细。
还针对 Anaconda 这一 Python 运行环境的安装和运行,专门录制了视频。

但是,工作坊现场遇见的问题,依然五花八门。
有的是操作系统。例如你可能用Windows 10。实话实说,我确实没用过。拿着Surface端详,连安装后的Anaconda文件夹都找不到在哪儿。
有的是编码。不同操作系统,有的默认中文编码是UTF-8,有的是GBK。同样一段中文文本,我这里显示一切正常,你那里就是乱码。
有的是套件路径。来参加工作坊前,你可能看过我一些教程,并安装了 Python 2.7 版本 Anaconda。来到现场,一看需要 Python 3.6 版本,你就又安装了一份新的。结果执行起来,你根本分不清运行的 Python, pip 命令来自哪一个套件,更搞不清楚软件包究竟安装到哪里去了。再加上虚拟环境配置,你就要抓狂了。
还有的,甚至是网络拥塞问题。因为有时需要现场安装调用体积庞大的软件包,几十台电脑"预备——齐"一起争抢有限的Wifi带宽,后果可想而知。
痛定思痛,我决定改变一下现状。
目前的教程只提供基础源代码。对于许多新手同学来说,是不够的。
许多同学,就倒在了安装依赖软件包的路上,继而干脆放弃了。
变通的办法有许多。例如干脆录制代码执行视频给你看。
但是正如我在《MOOC教学,什么最重要?》一文中说过的,学习过程里,反馈最重要。
你需要能运行代码,并且第一时间获得结果反馈。
在此基础上,你还得能修改代码,对比前后执行结果的差别。
我得给你提供一个直接可以运行的环境。
零安装,自然也就没了上述烦恼。
这个事儿可能吗?
我研究了一下,没问题。
只要你的设备上有个现代化浏览器(包括但不限于Google Chrome, Firefox, Safari和Microsoft Edge等)就行。
IE 8.0?
那个不行,赶紧升级吧!
读到这里,你应该想明白了。因为只挑浏览器,不挑操作系统,所以别说你用Windows 10,你就是用iPad,都能运行代码。
尝试
请你打开浏览器,输入这个链接(http://t.cn/R35fElv)。
看看会发生什么?
我这里用iPad给你演示。
一开始会有个启动界面出来。请你稍等10几秒钟。

然后,你就能看到熟悉的Python代码运行界面了。
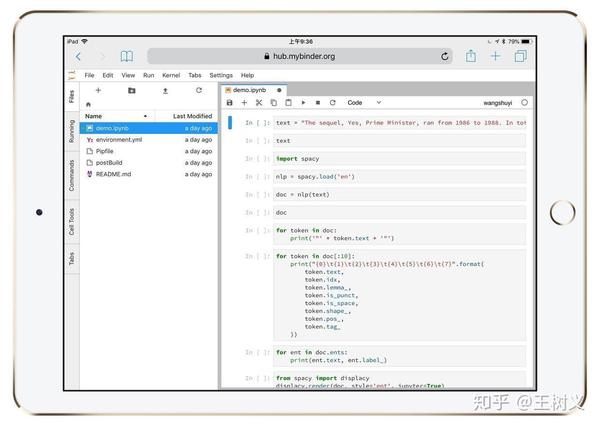
这个界面来自 Jupyter Lab。
你可以将它理解为 Jupyter Notebook 的增强版,它具备以下特征:
- 代码单元直接鼠标拖动;
- 一个浏览器标签,可打开多个Notebook,而且分别使用不同的Kernel;
- 提供实时渲染的Markdown编辑器;
- 完整的文件浏览器;
- CSV数据文件快速浏览
- ……
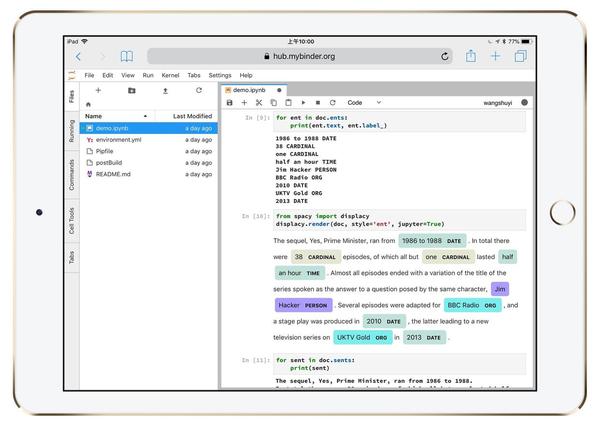
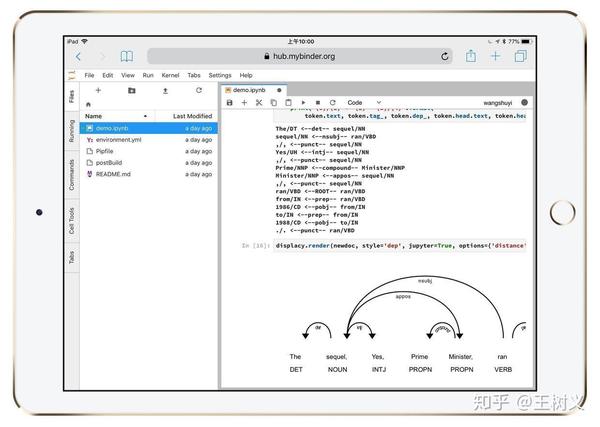
图中左侧分栏,是工作目录下的全部文件。
右侧打开的,是咱们要使用的ipynb文件。
为了证明这不是逗你玩儿,请你点击右侧代码上方工具栏的运行按钮。
点击一下,就会运行出当前所在代码单元的结果。
不断点击下来,你可以看见,结果都被正常渲染。
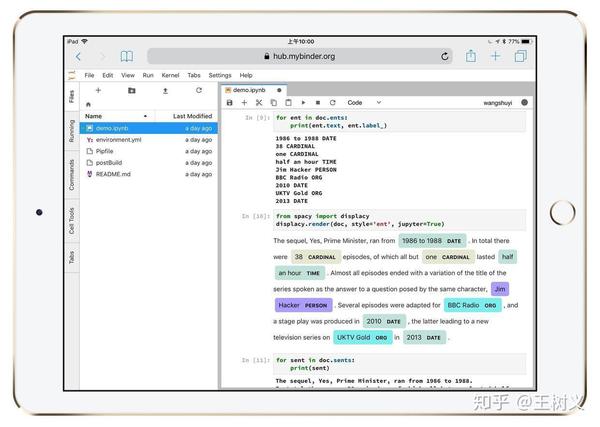
连图像也能正常显示。
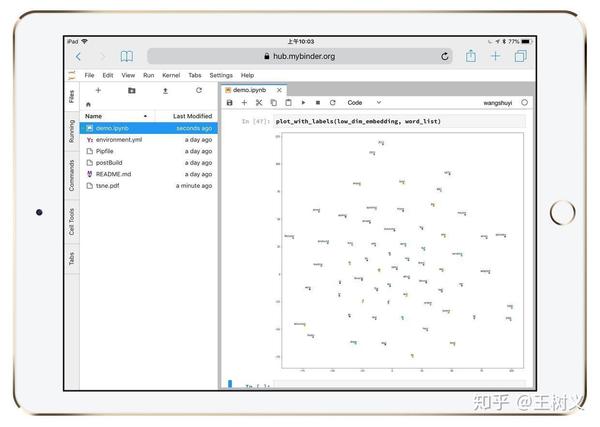
甚至连下面这种需要一定运算量的可视化结果,都没问题。
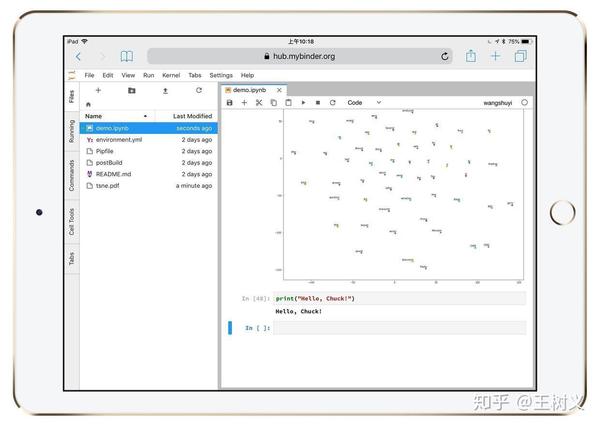
为了证明这不是变魔术,你可以在新的单元格,写一行输出语句。
就让Python输出你的名字吧。
假如你叫 Chuck,就这样写:
print("Hello, Chuck!") 把它替换成你自己的姓名,看看输出结果是否正确?
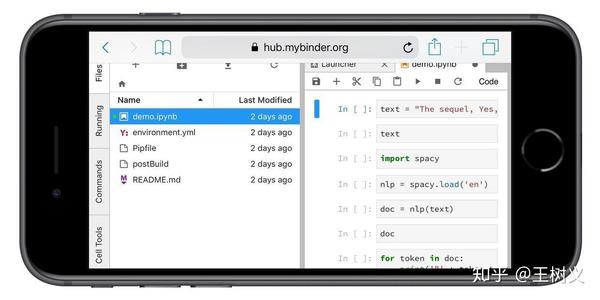
其实,又何止是iPad而已?
你如果足够勇(sang) 于(xin) 尝(bing) 试(kuang),手机其实也是可以的。
就像这样。
流程
下面我给你讲讲,这种效果是怎么做出来的。
我们需要用到一款工具,叫做 mybinder 。它可以帮助我们,把 github 上的某个代码仓库(repo),快速转换成为一个可运行的环境。
注意 mybinder 为我们提供了云设施,也就是计算资源和存储资源。因此即便许许多多的用户同时在线使用同一份代码转换出来的环境,也不会互相冲突。
我们先来看看,怎么准备一个可供 mybinder 顺利转换的代码仓库。
我为你提供的样例在这里(http://t.cn/R35MEqk):
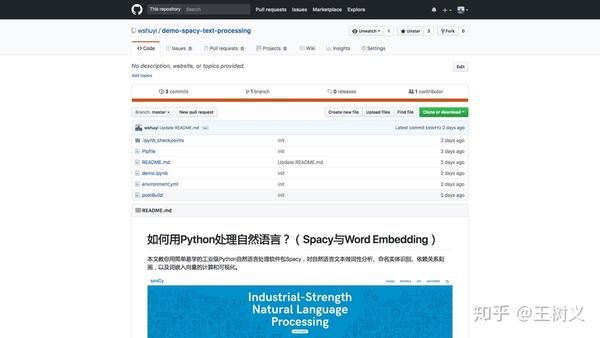
顺便说一句,这个样例来自于我的数据科学系列教程之《如何用Python处理自然语言?(Spacy与Word Embedding)》。感兴趣的同学可以点击链接,查看原文。
在该 GitHub 页面展示的文件列表中,你需要注意以下3个文件:
demo.ipynb
environment.yml
postBuild
其中demo.ipynb就是你在上一节看到的包含源代码的Jupyter Notebook文件。你需要首先在本地安装相关软件包,并且运行测试通过。
如果在你本地运行都有错误,放到云上去,想必也难以正常运行。
environment.yml文件非常重要,它来告诉 mybinder ,需要如何为你的代码运行准备环境。
我们打开看看该文件的内容:
dependencies: - python=3 - pip: - spacy - ipykernel - scipy - numpy - scikit-learn - matplotlib - pandas - thinc 这个文件首先告诉 mybinder ,你的 Python 版本。我们采用的是 3.6 版。所以只需要指定 python=3 即可。mybinder 会自动为你下载安装最新的。
然后这个文件说明需要使用 pip 工具安装哪些软件包。我们需要把所有依赖的安装包都罗列出来。
这就是之前,我总在教程里给你说明的那些准备步骤。
但是这还没有完,因为 mybinder 只是为你安装好了一些软件依赖。
这里还有两个步骤需要处理:
- 为了分析语义,我们需要调用预训练的Word2vec模型,这需要 mybinder 为我们提前下载好。
- Jupyter Notebook 打开后,应当使用的 kernel 名称为 wangshuyi ,这个 kernel 目前还没有在 Jupyter 里面注册。我们需要 mybinder 代劳。
为了完成上述两个步骤,你就需要准备最后一个postBuild文件。
它的内容如下:
python -m spacy download en python -m spacy download en_core_web_lg python -m ipykernel install --user --name=wangshuyi 跟它的名字一样。它是在 mybinder 依据 environment.yml 安装了依赖组建后,依次执行的命令。如果你的代码需要其他的命令提供环境支持,也可以放在这里。
至此,你的准备工作就算结束了。
魔法表演正式开始。
请打开 mybinder 的网址(https://mybinder.org/)。
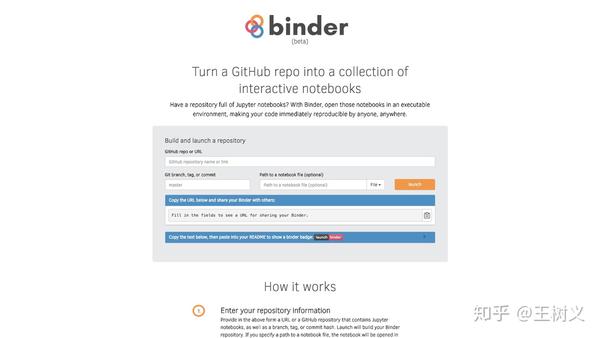
在 "GitHub repo or URL" 一栏,填写我们的 github 代码仓库链接,即:
https://github.com/wshuyi/demo-spacy-text-processing 我们希望一进入界面,就自动打开 demo.ipynb ,因此需要在"Path to a notebook file (optional)"一栏填写demo.ipynb 。
这时,你会发现"Copy the URL below and share your Binder with others:"一栏中,出现了你的代码运行环境网址。
https://mybinder.org/v2/gh/wshuyi/demo-spacy-text-processing/master?filepath=demo.ipynb 点击右侧的"复制"按钮保存到你的记事本里面。将来找到你转换好的运行环境,就全靠它了。
妥善保存地址后,点击"Launch"按钮。
根据你的依赖安装包数量等因素,你需要等待的时间长短不一。但是只有第一次构建的时候,需要花一些时间。
以后每一次调用执行,就都会非常快了。
构建完毕后, mybinder 会自动为我们开启对应的运行环境。
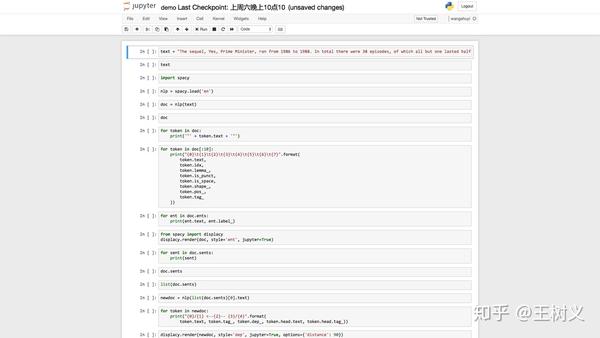
很有成就感吧!
测试一下,能够正常运行代码,就证明我们成功了。
但是你会发现,不对啊!
老师你刚才用 iPad 展示的,不是高级版的 Jupyter Lab 吗?怎么又变成了 Jupyter Notebook 了?
我也想要高级版!
别着急。
看看你目前的链接地址:
https://mybinder.org/v2/gh/wshuyi/demo-spacy-text-processing/master?filepath=demo.ipynb 你只需要做个小小的调整,将其中的:
?filepath= 替换为:
?urlpath=lab/tree/ 替换后的链接为:
https://mybinder.org/v2/gh/wshuyi/demo-spacy-text-processing/master?urlpath=lab/tree/demo.ipynb 把它输入到浏览器,看看出来的结果:
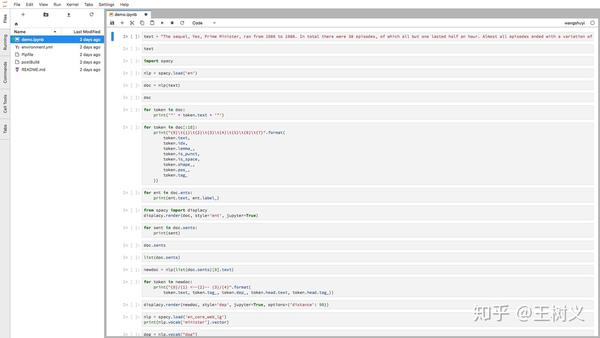
这下没问题了吧?
原理
你是不是觉得,mybinder 很黑科技?
其实,也不算。
它只是把已有的几项技术,链接了起来。
这大概也算是"积木式创新"的一个实例吧。
我们看看 mybinder 的说明:
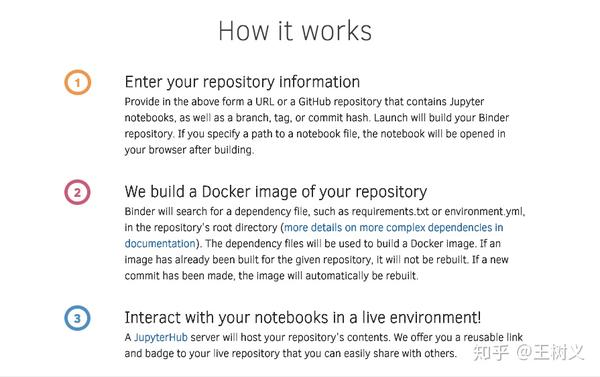
可以看到,其中最为关键的技术,是用了 docker 。
Docker 是个什么东西呢?
简单来说,Docker 就是为了不同平台上,都能够顺利执行同一份代码的保障工具。
你有些犹疑,这说的不是 Java 吗?
没错,Java 的宣传口号,就是一次编码,各处运行。
它利用虚拟机,来保障这种能力。
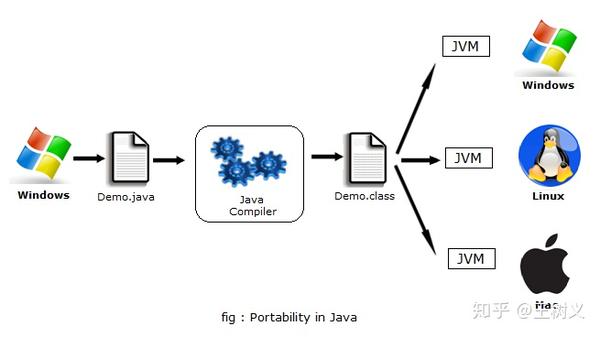
但是,如果你经常使用 Java 开发出来的工具,就应该了解痛点有哪些了。
至少,你应该对 Java 程序的运行速度,有一些体会。

上图中,左侧是虚拟机,右侧是Docker。
Docker 不但效率上要强过 Java 虚拟机,而且它支持的编程语言也不仅仅是一种。
至于其他好处,咱们就不展开了。否则听起来像广告。
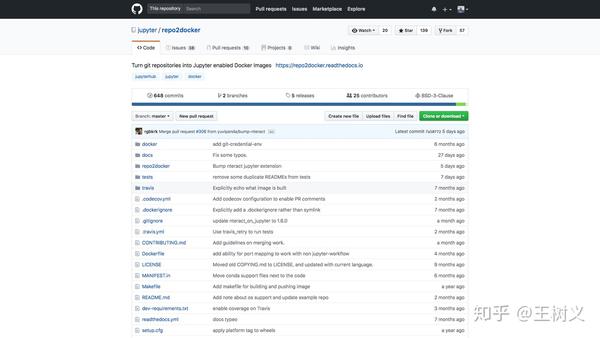
其实,把 github 代码仓库转换为 docker 镜像(image)的工作,也不是 mybinder 自己来做的。
它调用的,是另外的一个工具,叫做 repo2docker(https://github.com/jupyter/repo2docker) 。
而你的浏览器能够执行 Python 代码,是因为 Jupyter Notebook (或者Lab)本来就是建立在"浏览器/服务器"(Browser / Server, B/S)结构上。
如果你已经在本地计算机安装过 Anaconda ,那不妨看看本地执行这个语句:
jupyter lab 会出现什么?
对,它开启了一个服务器,然后打开你的浏览器,跟这个服务器通讯。
Jupyter 的这种设计,本身就让它的扩展极为方便。
无论 Jupyter 服务器是运行在你的本地笔记本上,还是摆在另一个大洲的机房,对你执行 Python 代码来说,都是没有本质区别的。
另外,如果你以为 mybinder 只能让你在浏览器上跑 Python 代码,那就太小瞧它了。
学过 R 的同学,请点击这个链接(http://t.cn/R3JLY2S),看看有什么惊喜。
小结
总结一下,本文为你讲述了以下内容:
- 如何利用 mybinder ,把一个 github repo 一键转换成 Jupyter Lab 运行环境;
- 如何在各种不同操作系统的浏览器上,运行该环境,编写、执行与修改代码;
- mybinder 转换 github repo 的幕后英雄 docker 简介。
我希望你能想到的,不仅仅是这点儿简单的用途。
提几个问题给你,作为思考题:
- 如果代码执行都在云端完成,教学实验室机房还有没有必要预装一大堆软件,且不定期更新维护?
- 学校的编程练习、作业和考试有没有可能通过这种方式,直接远程进行,并且自动化评分?
- 既然应用的技术都是开源的,你有没有可能利用这些开源工具搞个创业项目。例如提供深度学习环境,租赁给科研机构与创业公司?
期待你举一反三,做出有趣又有意义的创新来。
讨论
在 iPad 上运行 Python 代码的感觉怎么样?你用过类似的产品吗?你觉得有了这种技术,在日常工作和学习中,还可以有哪些有趣的应用场景?欢迎留言,把你的经验和思考分享给大家,我们一起交流讨论。
如果你对我的文章感兴趣,欢迎点赞,并且微信关注和置顶我的公众号"玉树芝兰"(nkwangshuyi)。
如果本文可能对你身边的亲友有帮助,也欢迎你把本文通过微博或朋友圈分享给他们。让他们一起参与到我们的讨论中来。
延伸阅读
来源:知乎 www.zhihu.com
作者:王树义
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载
没有评论:
发表评论